操作系统虚拟内存发展史
混沌岁月
开天辟地之初,早期的内存并没有什么复杂的抽象,物理内存简单粗暴。
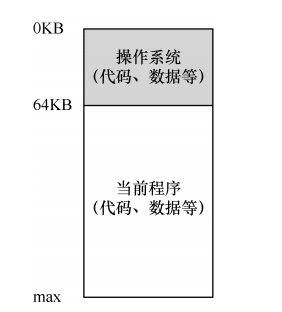
想要写什么?给,物理地址给你,随便搞。这样的操作系统并没有担负起它该有的责任,反而更像一个函数库,给了你一些系统调用之类的函数,开发人员很自由。
过了一段时间,多程序时代来临。怎么让这些程序有条不紊地运行,成为了一个必须考虑的问题。例如是给一个程序所有地址空间还是一部分,地址空间如何分配,如果有程序不小心或恶意访问、修改其他程序该怎么办?操作系统,起来干活了!
CPU利用了时分共享来应对多程序时代,每个程序跑一段时间,自动让出CPU,或者时钟中断之后CPU切换到操作系统,操作系统来调用程序,应用一系列策略来决定下一个时间片谁使用CPU。
问题到了内存这里,内存又将采用何种策略应对新的时代?
左右横跳
一种方法是轮到哪个进程就把全部的内存都给它,结束之后将所有内存,寄存器全部保存到硬盘,然后把内存给下一个程序使用,问题在于,磁盘很慢,以前的机械硬盘更慢。
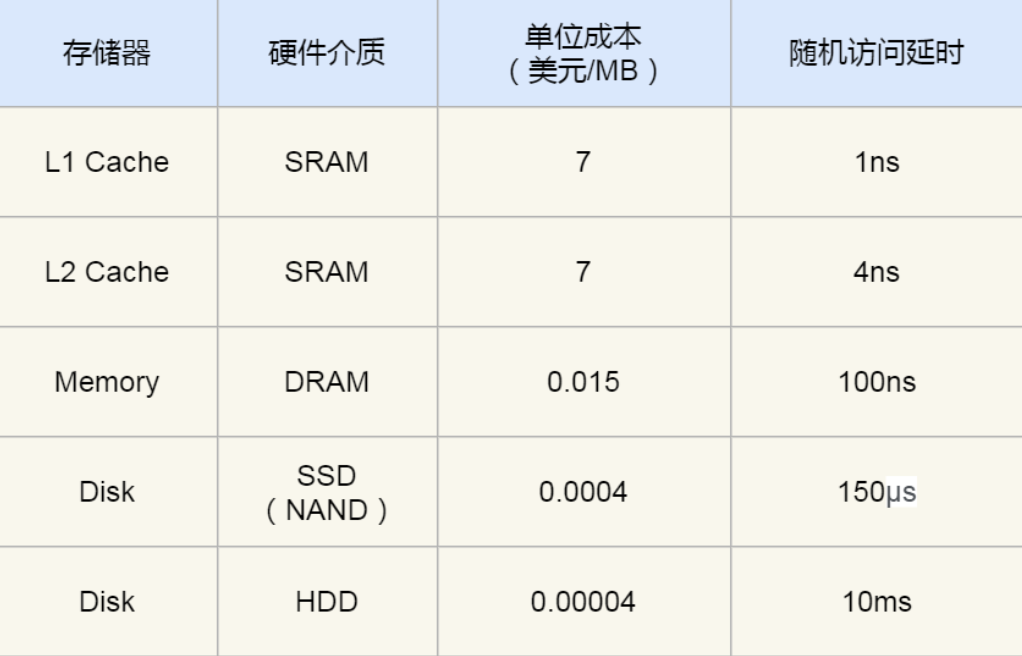
内存和机械硬盘差了五个数量级,在内存和磁盘之间横跳太慢了。
各自为王
与上一种方法作对比,很明显,也可以一个进程只占用部分内存,每个进程可以在各自内存区间里进行活动。
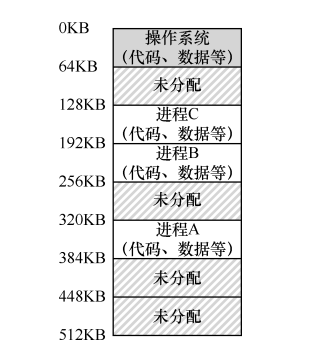
目前,我们的问题就到了程序这里了,不是占用整个内存了,而是由操作系统给你分配内存区间。那写程序地址怎么办?如上图的进程C,如果C妄图攻打进程B的地址区间怎么办?CPU提供了两个寄存器来解决,基址寄存器和界限寄存器。基址寄存器负责提供进程从哪开始,界限寄存器负责监督进程超界了没有,超界了由CPU进行对应的处理,一般是直接挂掉它。上图中,程序只需要当做自己的64KB地址是从0开始的就好,地址转换由硬件进行。
上面的硬件地址转换看起来不错,可是仍旧有个问题:64KB对于有的进程太大了怎么办?岂不是造成了内存浪费,内存可是十分昂贵的,经不起浪费啊!
64KB对于现在的进程来说太小了,那是因为现在内存相对之前便宜了,我们都被惯坏了,一张图片都可以几兆。鼎鼎大名的《超级马里奥》才40KB。
进程及其地址空间如下:
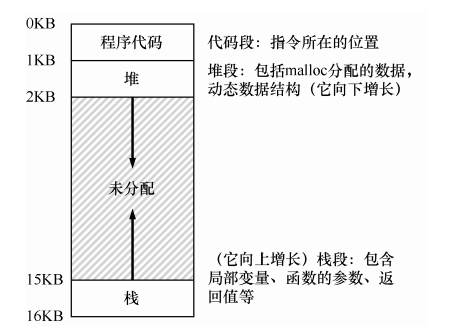
堆和栈之间可能存在大量的间隙没有用到,但是在物理内存里却占用了位置,这种浪费称为内存碎片。所以我们需要更复杂的机制,来更好地利用内存。
拆分王权
典型地址空间有三个逻辑不同的段:代码,堆,栈。既然堆、栈之间的未分配区域造成了内存碎片,那就更细化一点,不是将进程地址整个映射到物理地址,而是将不同的段分别映射到物理地址,当然,MMU(memory management unit)也就需要不止一对基址和界限寄存器。
那么,硬件地址转换如何知道引用了哪个段呢?可以在虚拟地址里面加两个标志位来表明;也可以通过地址产生方式来确定段,如是指令获取,或者栈指针,或者其他(堆)。
一个分配的例子如下:
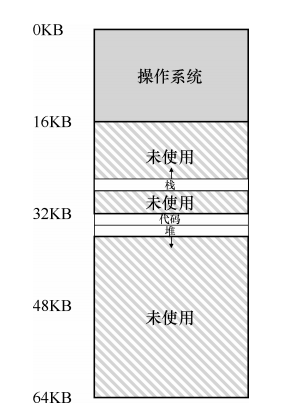
这里面,栈的硬件地址转换有所区别,因为它是反向增长。
为了节省内存(任何时候都是有必要的,内存在增加,但是应用的内存占用也在增加),出现了代码共享,这也就需要硬件提供保护位,来标识程序是否能都读写或者执行,同时不破坏隔离的思想。
操作系统在任务切换时需要负责保存各个寄存器的内容,新的地址空间被创建时,操作系统需要在物理内存中为它的段找到空间。碎片问题依然存在,这里称为外部碎片。
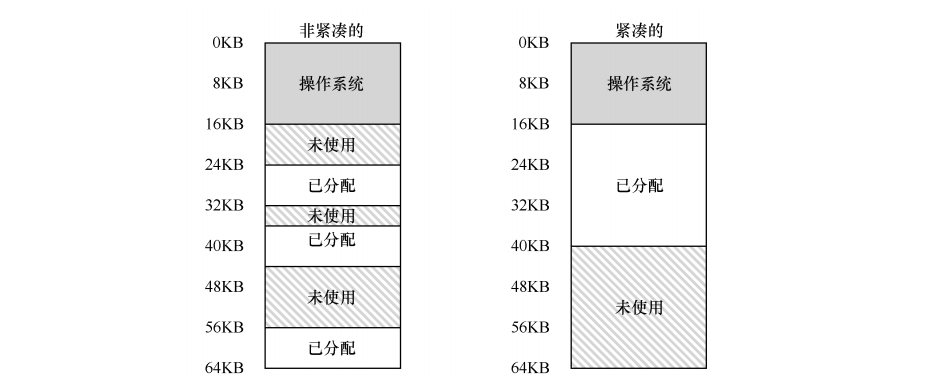
如果要分配一个20KB的段,左图明明有空间,却无法分配。
一种方法是:CPU负责整理,将他们的数据复制到连续内存区域,改变段寄存器值,如右图。但是这个操作成本很高。
更简单的方法就是通过空闲列表管理算法实现,尝试保留更大的内存块。具体的算法很多,但都无法完全消除外部碎片。
管理的烦恼
就像去餐馆吃饭,每个四人桌都坐了一个人,来了四个人一起吃饭,一看空位几十个,但是就是没有空闲的四人桌,啪的一下心情就不愉悦了。
所以这一节的主题就是如何管理空闲空间。
栈是自动管理的,压进弹出不需要我们操心,我们要关心的是堆。在堆上管理空闲空间的数据结构就是上文提到的空闲列表。
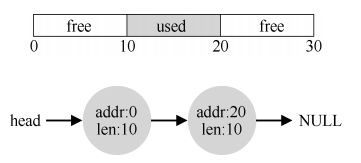
会堆空间的申请释放都会体现在空闲列表上。当上图used释放时,列表会表现为三段空闲的区域,这个时候很自然的一个策略是合并相邻空闲块。记住,我们的总体目标是要有尽可能大的连续空闲区域。
分配策略
内存的分配释放是任意的,内存可能会被搞得稀碎,理想的分配程序应该保证快速和碎片最小化。一个内存分配请求来了,该如何分配内存?
- 最优分配:遍历整个空闲链表,找到符合要求的地址区间最小的。避免了空间浪费,但是性能差。
- 首次匹配:遍历,找到了符合条件的地址区间就结束。空闲列表开头会被分裂成很多小块。
- 下次匹配:比首次匹配多维护一个指针,指向上一次查找结束的位置,就是为了避免首次匹配空闲列表开头频繁分割的问题。
一些有趣的方式
分离空闲列表
对于应用程序频繁申请的一种或几种大小的内存空间,用一个独立的列表来管理,其他的给通用内存分配程序。
伙伴系统
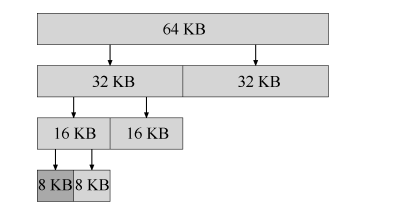
这个是为了合并空闲内存更加简单,思路就是将空闲空间一分为二,直到找到小的不能再小的地址区间,返回给用户。合并的时候只要查看相邻区间,就可以直到是否可以合并。
没有规矩,不成方圆
分段将空间切成不同大小的分片之后,空间会碎片化,再想合回来就难了。一种对应的解决方法是将空间分割成固定长度的分片,称为分页。

操作系统为每个进程保存一个数据结构,来记录地址空间虚拟页在物理内存的位置,称为页表。主要用来进行地址转换。
上图的例子中,地址空间为64字节,所以虚拟地址需要6位。页大小为16字节,所以页面号要两位,偏移量4位。
进行地址转换的时候就根据页面号和偏移量查找页表项,找到期望的物理帧号(PFN)。
如x86页表项如下:

20位的物理帧号,4KB的页面,正好32位。页表项后面几位则是标志位,如读写为R/W,访问位A等。
页表放在哪里?当然是放在内存里,那样每一个内存引用都要执行一个额外的内存引用来从页表获取地址转换。时间翻倍!而且页表内存占用很大,算一笔账,以上面的x86为例,一个页表项32位,4个字节。一个页帧4KB,那样就有2的20次方个页帧,一个页帧对应一个页表项,也就是2的24次方字节,就是4MB。系统后台可能有上百个进程,光是页表就占了400MB以上,这河狸吗?

问题摆在这,后面讨论如何解决。
拨云见日
使用分页作为核心机制来实现虚拟内存,性能开销较大,那如何加速地址转换呢?
软件上想不通的,就要由硬件来提供帮助,而且很多时候硬件的一些略微的改变,会带来巨大的性能提升。这里就是要增加地址转换旁路缓冲存储器(translation-lookaside buffer, TLB),或者称为地址转换缓存。还记的上面的访问速度图吗,cache超快的。每次内存访问,先看一下TLB,如果有就很快完成转换,不再访问页表,没有就需要去查页表了。redis和传统数据库的组合不就是很像这个做法吗?
初学编程的时候,老师告诉你,内存最好是连续访问,例如二维数组,你应该a[0][0],a[0][1],a[0][2]这样遍历,而不是a[0][0],a[1][0],a[2][0]这样去遍历,现在你知道原因了吗?就是和地址转换缓存的命中率有关。
典型的TLB有32项、64项或者128项。硬件会并行查找期望的转换映射。
同样,页表,TLB都只是对一个进程有效,上下文切换时会进行切换。一种方法是简单清空TLB,如有效位置0。如果操作系统频繁切换进程,这种每次进程运行都会触发TLB未命中。
或者增加硬件支持,增加进程标识符。这样就不用了清零了。那新缓存来了,替换哪一个呢?
一种常见的策略是替换最少使用的项(LRU),另一种典型策略就是随机替换,来防止极端情况。
速度问题有了解决办法,那空间问题呢?4MB的问题还是存在啊!
之前我们默认说的都是线性页表,一种方法是采用更大的页。很明显,页更大了,页表里面的项就更少了,内存占用也就少了。但是页太大会造成内部碎片,空间浪费。
古语有言:取其精华去其糟粕。结合分页和分段机制也是一种方法。这种方法就是抛去了堆和栈之间的空闲区域,不再映射物理内存,也没有页表,来节省空间。
数据结构的强大之处来了。线性列表解决不了,换个结构试试,出现了多级页表,类似树的结构。
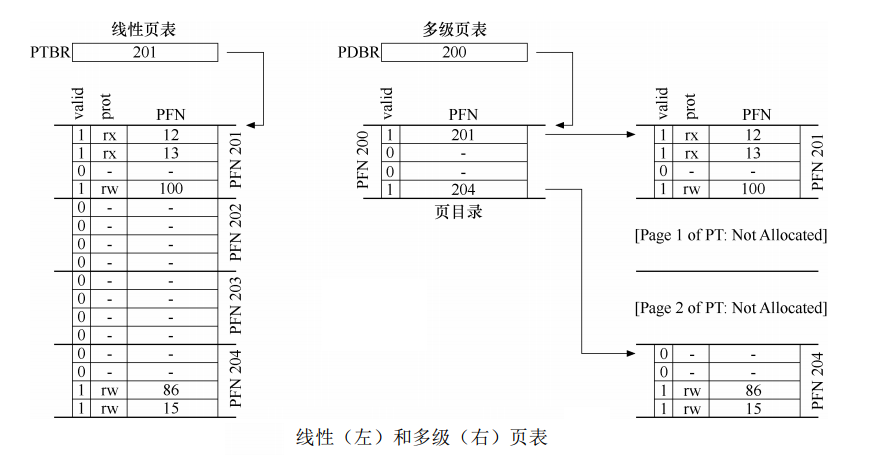
多级页表增加了页目录的概念,用来标记一个页是否是无效页,无效就没有页表项。成本就是TLB未命中时需要从内存加载两次,一次页目录,一次PTE。
页目录还是太大怎么办?再加一层页目录。。。
更极端一点,有反向页表。他就是一个页表记录所有进程的地址映射,无效的不记录,页表项里标识哪个进程或哪些进程在用这个地址映射。线性查找自然不现实,这种做法的查找应该是建立散列表来加速查找。
之前说过一句:页表放在哪?当然是内存。这句话也不绝对,对于大部分内存都不绝对,内存不够用时,操作系统会将一部分不常用的内存放入磁盘,称为交换空间。
尘埃落地
至此,虚拟内存的大致脉络已经清晰,它是软硬件,数据结构,算法的结合,是空间和时间的权衡。