一些java基础知识
写时拷贝技术(Copy-on-Write)
是计算机优化的一种策略,如果多个调用者同时要获取相同的资源(如内存或者磁盘上的数据存储),它们会获取相同的指针指向同一份资源,直到有一个调用者要修改资源,系统才会真的复制一份副本给调用者,而其它调用者仍然用最初的资源。
如 Linux 的
fork()和exec()函数。如果将父进程数据全部拷贝到子进程,子进程执行exec()后数据清空,前面的复制就无效了,所以有了COW。在网上看到还有个细节问题就是,fork之后内核会通过将子进程放在队列的前面,以让子进程先执行,以免父进程执行导致写时复制,而后子进程执行exec系统调用,因无意义的复制而造成效率的下降。
fork之后,kernel 把所有的内存页权限设为只读,然后父进程地址空间指向父进程。当其中一个进程要修改内存时,触发异常。
Java 的 COW:
java 中也有两个容器使用了 COW 机制,CopyOnWriteArrayList和CopyOnWriteArraySet。
以CopyOnWriteArrayList为例,源码部分如下:
public class CopyOnWriteArrayList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable {
/** The lock protecting all mutators */
final transient ReentrantLock lock = new ReentrantLock();
/** The array, accessed only via getArray/setArray. */
private transient volatile Object[] array;
final Object[] getArray() {
return array;
}
final void setArray(Object[] a) {
array = a;
}
。。。
}
可见,其底部使用一个对象数组,只能通过getArray/setArray访问。
读是直接返回array,其它修改操作呢?如add操作:
// 整个过程由可重入锁保护
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
// 获取原来的数组
Object[] elements = getArray();
int len = elements.length;
// 拷贝出新数组
Object[] newElements = Arrays.copyOf(elements, len + 1);
// 新数组add一项
newElements[len] = e;
// 将原数组引用指向新数组
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
适合频繁读偶尔写的操作,写的时候需要获取锁和对数组进行复制处理,存在性能问题。
异常处理
如登录逻辑:

优雅的处理是约定 code 和 message ,如 0 表示成功,1 代表第一次登录,跳转重置页面,-1 表示登录失败, message 描述返回信息。后端统一异常处理。
程序中的错误大致可以分为三大类:
- 系统错误。这类错误是程序运行环境的问题,一般我们都无法避免,对于这类错误,有些我们是可以处理的,比如请求网络异常,这个我们可以重试几次,而有些是我们无法处理的,比如内存耗尽 OOM 了、栈溢出等等,这种我们就只能停止运行,甚至退出整个程序。
- 程序错误。这类错误一般都是我们程序的 bug,比如空指针,文件未创建,逻辑计算错误,对于这种错误,我们必须要记录下来,而且最好是触发监控系统告警。
- 用户错误。比如用户输入非法参数,重复请求,一般这类的错误属于用户应用层错误,对于这类错误,我们只需要提示用户即可,没有必要记录日志,但是我们可以做一些必要的统计,比如某个用户频繁输入非法参数,不断进行错误请求,我们可以将这些用户纳入黑名单等,这样有利于我们改善系统和侦测是否有恶意的用户请求。
例如异常分类:
BusinessException:业务异常,继承RuntimeExceptionNotFountException:业务异常,继承RuntimeExceptionParamValidateException:业务异常,继承RuntimeExceptionSystemException:系统异常,继承Exception
1、2、3 不需要显示处理,4 一定需要处理。然后再配合两个枚举:
BusinessErrorCodeEnumSystemErrorCodeEnum
监控系统会实时将系统的 Error 、Exception 告知相关的开发人员,这样我们就能及时发现系统这个的错误,及时响应,缩小影响范围。
实现一个LRU
LRU: Least Recently Use。就是淘汰掉最先访问的数据。
LinkedHashMap:有序,key和value允许空,key重复会覆盖,非线程安全。它既使用HashMap操作数据结构,又使用LinkedList维护插入元素的先后顺序。
public class LinkedHashMap<K,V>
extends HashMap<K,V>
implements Map<K,V>
{
。。。
}
LinkedHashMap的基本数据结构是Entry:
// LinkedHashMap##Entry
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after; // 维护Entry插入的先后顺序
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
// HashMap##Node
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next; //指定table位置连接Entry的顺序
...
}
初始化:
LinkedHashMap<String,String> map = new LinkedHashMap<>();
map.put("123","value123");
map.put("456","value456");
在构造函数中:
// The iteration ordering method for this linked hash map: true
// for access-order,false for insertion-order.
// final boolean accessOrder;
public LinkedHashMap() {
super();
accessOrder = false;
}
这里accessOrder选择是按插入排序还是按访问排序。
示意图:
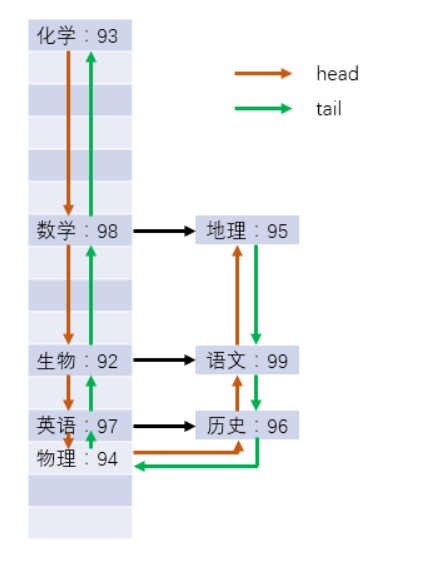
LinkedHashMap使用示例:
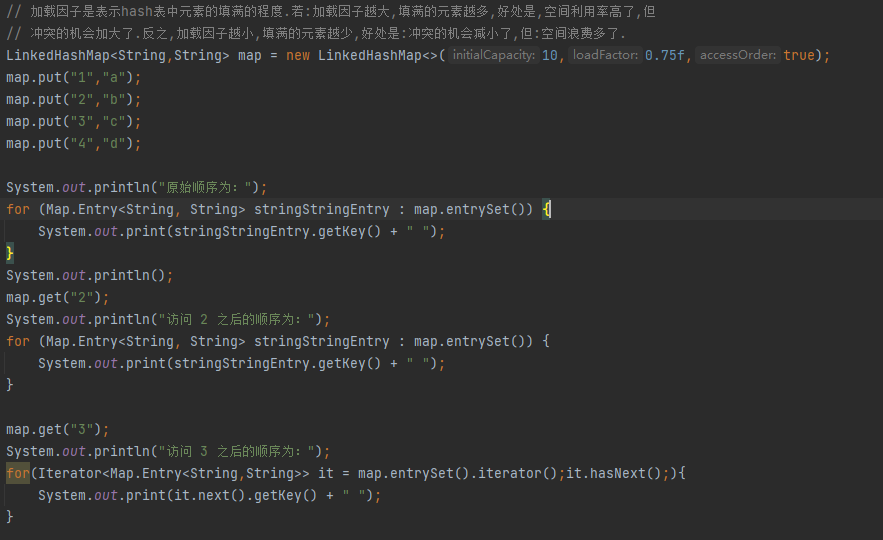
结果(最右边是最先插入或者刚访问过的):
原始顺序为:
1 2 3 4
访问 2 之后的顺序为:
1 3 4 2
访问 3 之后的顺序为:
1 4 2 3
LRU实现:在LinkedHashMap基础上设置容量,超过删除;保证线程安全。可以选择继承它重写方法。
先不考虑线程安全,直接继承。
public class LRU extends LinkedHashMap {
int capacity;
public LRU(int capacity) {
// 按访问顺序排序
super(capacity,0.75f,true);
this.capacity = capacity;
}
// 只需重写是否超过,在调整顺序的时候会执行删除操作
//void afterNodeInsertion(boolean evict) { // possibly remove eldest
// LinkedHashMap.Entry<K,V> first;
// if (evict && (first = head) != null && removeEldestEntry(first)) {
// K key = first.key;
// removeNode(hash(key), key, null, false, true);
// }
//}
@Override
protected boolean removeEldestEntry(Map.Entry eldest) {
System.out.println(eldest.getKey() + "=" + eldest.getValue());
return size()>capacity;
}
@Override
public Object get(Object key) {
return super.get(key);
}
@Override
public Object put(Object key, Object value) {
return super.put(key, value);
}
}
考虑线程安全,就不能直接继承了,可以将LinkedHashMap作为一个内部实例。
public class LRU<K,V>{
int capacity;
LinkedHashMap<K,V> map;
public LRU(int capacity) {
// 按访问顺序排序
map = new LinkedHashMap<>(capacity,0.75f,true);
this.capacity = capacity;
}
public Object get(K key) {
return map.get(key);
}
public void put(K key, V value) {
synchronized(this) {
map.put(key,value);
if(map.size()>capacity) {
Iterator<K> iterator = map.keySet().iterator();
map.remove(iterator.next());
}
}
}
}