短链接系统设计、布隆过滤器
短连接背后的原理?如何实现?系统怎么设计?
考虑长度
如6位随机码的形式:abCDEf
一位是52个可能(只算字母的话),6位大概能容纳197亿个链接。可以自行设计长度。
重定向
http状态码:
- 1**:服务器收到请求,需要请求者继续执行操作
- 2**:成功,200 OK,204 No Content,206 Partial Content。。。
- 3**:重定向
- 4**:客户端错误,401 Unauthorized,403 Forbidden,404 Not Found。。。
- 5**:服务端错误,500 Internal Server Error。。。
重点要关注的是3**重定向的状态码:
主要是:
301:永久重定向,浏览器会缓存,自动重定向到新的地址
302:临时重定向,客户端还是会继续使用旧的URL
跳转流程
- 用户访问短链接,请求到达服务器
- 服务器将短链接转为长链接,然后给浏览器返回301/302。
- 301永久重定向,浏览器会缓存重定向地址,短链接系统统计访问次数会不准确。
- 302临时重定向,问题在于都会经过服务器,压力比较大
- 浏览器拿到重定向的状态码,以及真正需要访问的地址,重定向到真正的长链接上。
url怎么存储
数据库
如果直接用自增id的形式:
| id | url |
|---|---|
| 1 | https://orzlinux.cn/blog/jdk-proxy-analyze.html |
那么访问时就访问:url.cn/1
存储可以考虑单机或者分布式,如redis来做自增。
id存储的缺点:
- 增长太快,1000000条就上七位了
- 不安全,规律性太强了
另一个id的实现可以是大小写字母加上数字。将数字id转为62进制,但是转换需要费时,可以直接在数据库里存储。这样短链接本质上还是递增的,可以随机将短链接字符打乱或者MD5等处理(冲突可以再重新生成)。
同时,还有短链接过期时间,要有相应的字段进行描述。过期就不予重定向。
缓存可以放到redis里面,根据数据库里面的时间设置过期时间。
或者对url进行摘要算法,进行移位、异或之类的操作,保证考虑到每个位,冲突的另外处理。
redis
直接redis关联长链接,短链接,设置过期时间,点击量,使用redis进行持久化操作。当时如果数据量很大放到单机内存有问题。可以将其作为缓存使用。
布隆过滤器解决无效访问
它说不存在一定不存在,它说存在可能存在。
判断元素是否在集合中,如垃圾邮件地址,比较容易想到的是map,但是数据量大的时候map占用的内存空间较大,如一个地址16字节,一亿个就是1.6G,几十亿个地址就是几十G内存。
典型的一个问题:如何在十亿个单词的字典中判断某个单词是否存在?
答:这个要分几种情况考虑。十亿个单词,不考虑map额外占用空间,单单每个单词算10字节的话,也需要10个G,对于现在电脑来说,就算单机的话,上个大的内存条也就可以了。但是电脑太拉的话,可以考虑分布式,每个电脑中存储一部分数据,同时向多个服务器请求,查到就是有,都没有就是没有出现。还有一种情况,如果允许一定的错误率的话,一般也很小,可以用布隆过滤器。
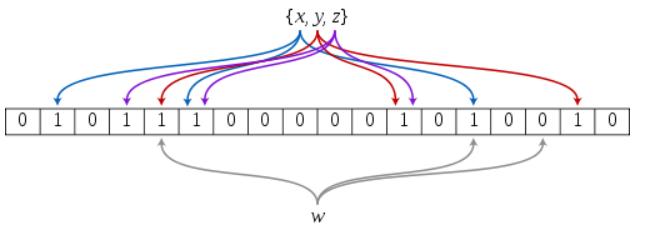
步骤:
- 建立一个大序列,如4亿字节,也就是400M,32亿个比特位,全部置0。
- 将信息多次映射(如8个)到序列的多个位上。全部置1。
- 查找的时候同样的方法判断这几个位是不是都为1。
错误率问题:
m为位数组的大小,n代表插入了n个元素,k是哈希函数的个数。
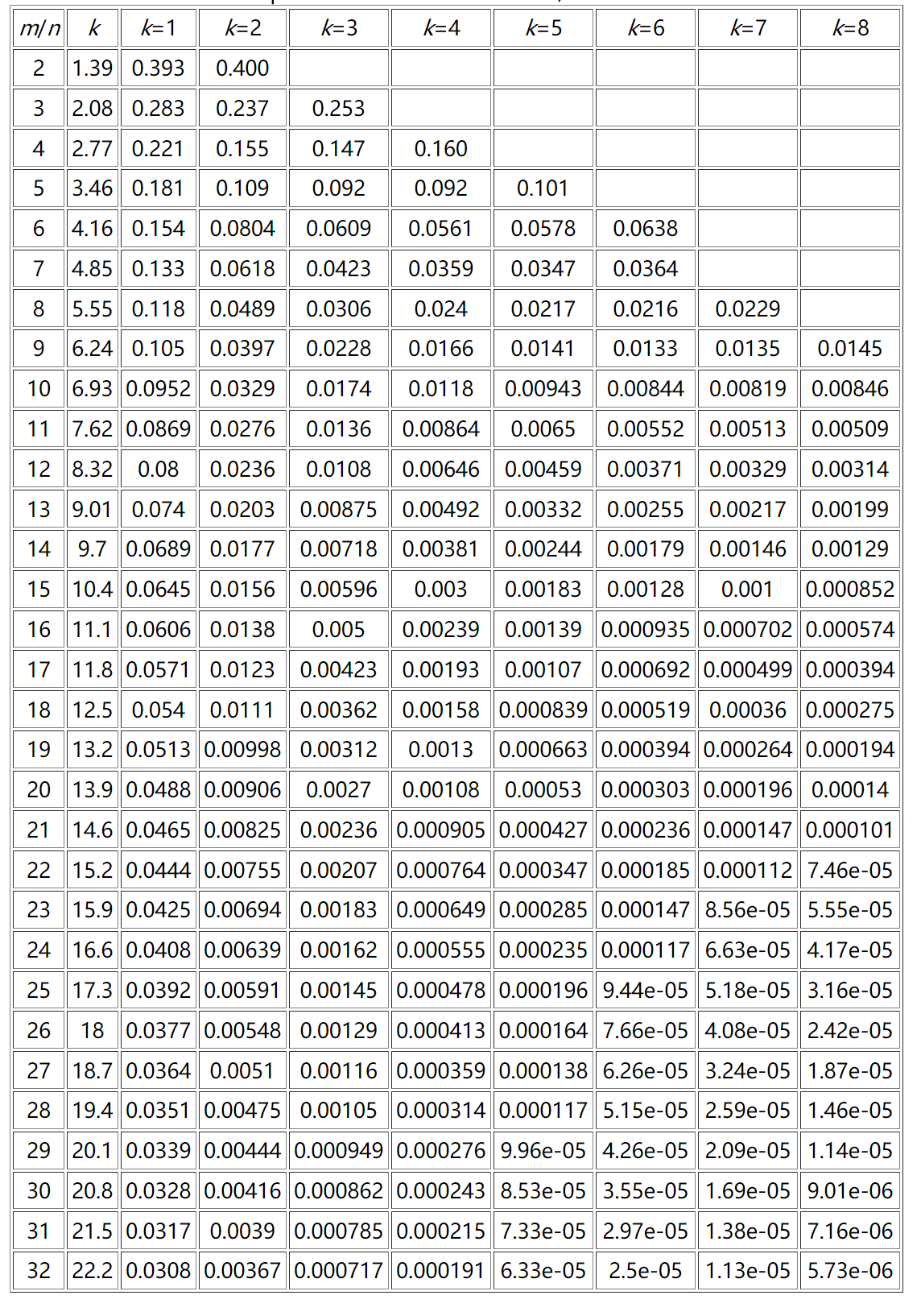
按照这个表来计算得话,如果想要达到错误率0.1%以下,应该用大概16n个比特,8个哈希函数。以十亿数据计算得话,要用2G内存,还是可以接受的。类似,8n个比特,7个哈希函数,也就是1G内存,也能达到98%的准确率。