Redis的一些常见问题
Redis主从同步不一致的问题
主从库间命令复制是异步进行的主库收到写命令后,会发送给从库。但是,主库并不会等到从库实际执行完命令后,再把结果返回给客户端,而是主库自己在本地执行完命令后,就向客户端返回结果了。如果从库还没有执行主库同步过来的命令或执行不及时,主从库间的数据就不一致了。
解决:尽量使用良好的硬件和网络环境,并实时做好监控。使用info replication 命令查看主库写命令进度(master_repl_offset)和从库复制写命令进度(slave_repl_offset),开发监控程序监控两者的差值,如果超过阀值则移除客户端对该从库的访问,避免数据不一致;如果两者差值恢复到阀值范围内,则重新调整客户端对从库的访问。
从库过期数据
1、从库不会同步执行主库删除命令,不会自动删除过期数据(主库读取到过期数据会自动删除)
2、时间差:比如主库设置60秒过期,是指主库执行的时间点往后60秒;该命令同步到从库后,是按从库执行时间点往后60秒,可能因为命令执行的时间差导致主库已过期,从库还没过期的情况
解决:时间差:尽量用EXPIREAT 和 PEXPIREAT,它们会把过期时间设置为具体的一个时间点(用时间服务器同步各个服务器的时钟)
Redis主从架构数据会丢失吗,为什么?
有两种数据丢失的情况:
- 异步复制导致的数据丢失:因为master -> slave的复制是异步的,所以可能有部分数据还没复制到slave,master就宕机了,此时这些部分数据就丢失了。
- 脑裂导致的数据丢失:某个master所在机器突然脱离了正常的网络,跟其他slave机器不能连接,但是实际上master还运行着,此时哨兵可能就会认为master宕机了,然后开启选举,将其他slave切换成了master。这个时候,集群里就会有两个master,也就是所谓的脑裂。此时虽然某个slave被切换成了master,但是可能client还没来得及切换到新的master,还继续写向旧master的数据可能也丢失了。因此旧master再次恢复的时候,会被作为一个slave挂到新的master上去,自己的数据会清空,重新从新的master复制数据。
如何解决主从架构丢失问题?
数据丢失的问题是不可避免的,但是我们可以尽量减少。数据复制和同步的延迟不能超过10秒。如果说一旦所有的slave,数据复制和同步的延迟都超过了10秒钟,那么这个时候,master就不会再接收任何请求了。
哨兵
定期向主、从、其他哨兵发PING。有效回复超阈值就认为下线。一个master被标记下线了,其他哨兵要定期确认master确实是下线了。一定数目哨兵认为master下线了,就标记为它确实下线了。
当Master被 Sentinel 标记为客观下线时,Sentinel 向下线的 Master 的所有 Slave 发送 INFO 命令的频率会从 10 秒一次改为每秒一次 (在一般情况下, 每个 Sentinel 会以每 10 秒一次的频率向它已知的所有Master,Slave发送 INFO 命令 )。
INFO命令:多行字符串文本行的合集每一行包含了包含一种信息或者属性(从#字符开始)。 所有的属性都是以字段:值(field:value)的形式,以\r\n结尾。
master挂了的话,哨兵结点们就会选举一个哨兵结点进行故障处理,从从结点中选取一个主结点。其他从节点挂载到新的主节点上自动复制新主节点的数据。
选主
首先进行筛选,把标记为下线的从库,网络不稳定的从库晒出掉。接下来进行打分,主要会分三个阶段:分别从 从库的优先级、复制进度、ID大小来进行打分。
同步配置的时候其他哨兵根据什么更新自己的配置呢?
版本号
Redis cluster节点间通信是什么机制?
Redis cluster节点间采取gossip协议进行通信,所有节点都持有一份元数据,不同的节点如果出现了元数据的变更之后,不断将元数据发送给其他节点让其他节点进行数据变更。
如果现在有个读超高并发的系统,用Redis来抗住大部分读请求,你会怎么设计?
少:一主多从+哨兵集群,主从复制,读写分离
多:Redis cluster,每个主节点存一部分数据。
分布式
分布式的 CAP 理论告诉我们:
任何一个分布式系统都无法同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance),最多只能同时满足两项。
数据库做分布式锁
- 唯一主键
- 表字段版本号,mysql mvcc
- 数据库排他锁 for update
Redis做分布式锁
分布式锁的三个核心要素
1、加锁
使用setnx来加锁。key是锁的唯一标识,按业务来决定命名,value这里设置为test。
setx key test
当一个线程执行setnx返回1,说明key原本不存在,该线程成功得到了锁;当一个线程执行setnx返回0,说明key已经存在,该线程抢锁失败;
2、解锁
有加锁就得有解锁。当得到的锁的线程执行完任务,需要释放锁,以便其他线程可以进入。释放锁的最简单方式就是执行del指令。
del key
释放锁之后,其他线程就可以继续执行setnx命令来获得锁。
3、锁超时
锁超时知道的是:如果一个得到锁的线程在执行任务的过程中挂掉,来不及显式地释放锁,这块资源将会永远被锁住,别的线程北向进来。
所以,setnx的key必须设置一个超时时间,以保证即使没有被显式释放,这把锁也要在一段时间后自动释放。setnx不支持超时参数,所以需要额外指令,
expire key 30
问题
1、SETNX 和 EXPIRE 非原子性
假设一个场景中,某一个线程刚执行setnx,成功得到了锁。此时setnx刚执行成功,还未来得及执行expire命令,节点就挂掉了。此时这把锁就没有设置过期时间,别的线程就再也无法获得该锁。
由于setnx指令本身是不支持传入超时时间的,而在Redis2.6.12版本上为set指令增加了可选参数, 用法如下:
SET key value [EX seconds][PX milliseconds] [NX|XX]
- EX second: 设置键的过期时间为second秒;
- PX millisecond:设置键的过期时间为millisecond毫秒;
- NX:只在键不存在时,才对键进行设置操作;
- XX:只在键已经存在时,才对键进行设置操作;
- SET操作完成时,返回OK,否则返回nil。
2、锁误解除
如果线程 A 成功获取到了锁,并且设置了过期时间 30 秒,但线程 A 执行时间超过了 30 秒,锁过期自动释放,此时线程 B 获取到了锁;随后 A 执行完成,线程 A 使用 DEL 命令来释放锁,但此时线程 B 加的锁还没有执行完成,线程 A 实际释放的线程 B 加的锁。
在del释放锁之前加一个判断,验证当前的锁是不是自己加的锁。具体在加锁的时候把当前线程的id当做value,可生成一个 UUID 标识当前线程,在删除之前验证key对应的value是不是自己线程的id。
3、超时解锁导致并发
如果线程 A 成功获取锁并设置过期时间 30 秒,但线程 A 执行时间超过了 30 秒,锁过期自动释放,此时线程 B 获取到了锁,线程 A 和线程 B 并发执行。
A、B 两个线程发生并发显然是不被允许的,一般有两种方式解决该问题:
- 将过期时间设置足够长,确保代码逻辑在锁释放之前能够执行完成。
- 为获取锁的线程增加守护线程,为将要过期但未释放的锁增加有效时间。
4、不可重入
当线程在持有锁的情况下再次请求加锁,如果一个锁支持一个线程多次加锁,那么这个锁就是可重入的。如果一个不可重入锁被再次加锁,由于该锁已经被持有,再次加锁会失败。Redis 可通过对锁进行重入计数,加锁时加 1,解锁时减 1,当计数归 0 时释放锁。
5、无法等待锁释放
上述命令执行都是立即返回的,如果客户端可以等待锁释放就无法使用。
- 可以通过客户端轮询的方式解决该问题,当未获取到锁时,等待一段时间重新获取锁,直到成功获取锁或等待超时。这种方式比较消耗服务器资源,当并发量比较大时,会影响服务器的效率。
- 另一种方式是使用 Redis 的发布订阅功能,当获取锁失败时,订阅锁释放消息,获取锁成功后释放时,发送锁释放消息。
Redis订阅
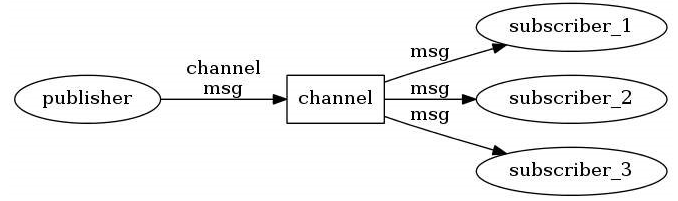
发布者和订阅者都是Redis客户端,Channel则为Redis服务器端,发布者将消息发送到某个的频道,订阅了这个频道的订阅者就能接收到这条消息。Redis的这种发布订阅机制与基于主题的发布订阅类似,Channel相当于主题。