kafka和秒杀的一些思想
kafka架构图
分析
用来处理海量数据流,写操作:写并发要求高,顺序追加写日志。
读操作相对比较简单,按照一定规则高效查找即可(offset,时间戳)。
如果是用MySQL中的B+树的话,每次写都要维护索引,还有数据页分裂问题,太重了。
哈希索引:内存中维护映射关系,根据offset查询时,从哈希表得到偏移量,再去读文件就可以快速定位到要读的数据位置。但是哈希表要常驻内存。容易把内存撑爆。
稀疏索引:类似分页二级目录。
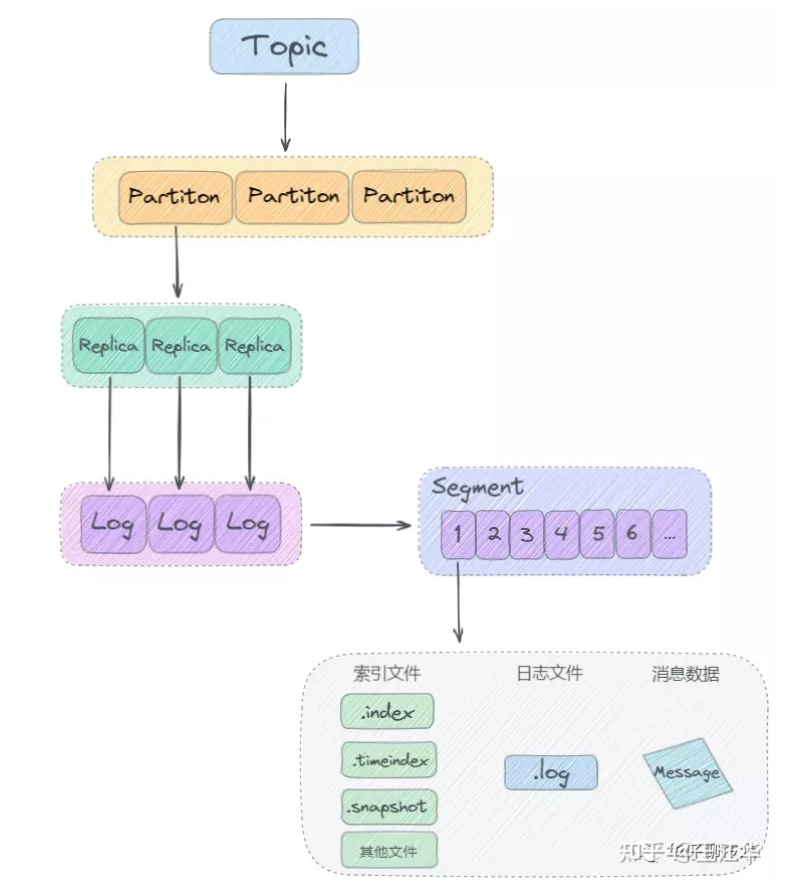
kafka中消息以topic为单位进行归类,topic是逻辑上的概念。实际上磁盘存储是根据分区partition存储的,每个topic被分为多个partition,分区的数量可以在topic创建的时候指定。
partition分区主要是为了解决存储的水平扩展问题设计的。如果一个topic只存储在一个broker上,,并发写入会出现瓶颈,故障不好回复,所以将topic消息划分成多个partition,然后均衡分不到broker集群中。
partition分区内每条消息都有一个offset,kafka只能保证分区内部有序,不能保证全局有序。
Log 切分为多个 LogSegement,相当于一个巨型文件被平均分割为一些相对较小的文件,这样也便于消息的查找、维护和清理。这样在做历史数据清理的时候,直接删除旧的 LogSegement 文件就可以了。
存储架构
顺序追加写日志,稀疏哈希索引。
如何实现超高并发写入
页缓存+磁盘顺序写。
零拷贝:消费数据从kafka的磁盘文件读取数据然后发送给下游的消费者。
如何保证数据不丢失
多副本,但是如果leader还没同步给follower就宕机了呢?
ISR(in-sync replica),要保证ISR至少有一个备份存活,并且消息提交成功。
秒杀并发读和并发写
高并发访问:分流、动静分离。
数据正确性:
减库存:事务,热点商品放到单独的热点库,增加并发锁。
异步化:把购买请求的接受和处理异步化。
限流。
秒杀系统读多写少,我们可以先将库存总数预热,存入redis中,使用信号量来控制秒杀请求的数量。
前端限流+后端限流。
限制每秒钟只能点击一次;限制总量;
后端快速失败、降级运行、熔断机制防止雪崩。