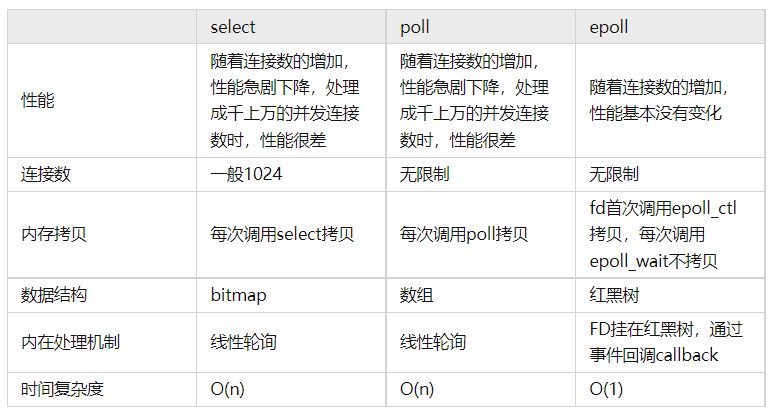
epoll、mysql的一些东西
select poll epoll具体实现
select
多路复用,多个socket连接复用一个线程。
fd_set里面是数组。
linux/posix_types.h头文件有这样的声明:
\#define __FD_SETSIZE 1024
typedef struct
{
/*XPG4.2requiresthismembername.Otherwiseavoidthename
fromtheglobalnamespace.*/
#ifdef__USE_XOPEN
__fd_maskfds_bits[__FD_SETSIZE/__NFDBITS];
#define__FDS_BITS(set)((set)->fds_bits)
#else
__fd_mask__fds_bits[__FD_SETSIZE/__NFDBITS];
#define__FDS_BITS(set)((set)->__fds_bits)
#endif
}fd_set;
select:
int select (int n, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
select 调用后会阻塞,直到有描述符就绪或超时。会将需要监控的集合拷贝到内核空间。然后挨个遍历检查是否有事件,如果都不可读,就阻塞,直到到时间了或者有数据可读了,遍历集合,然后将集合返回给用户层,只是此时的用户层得到的集合已经被OS做上标识,就不会有不必要的系统调用。
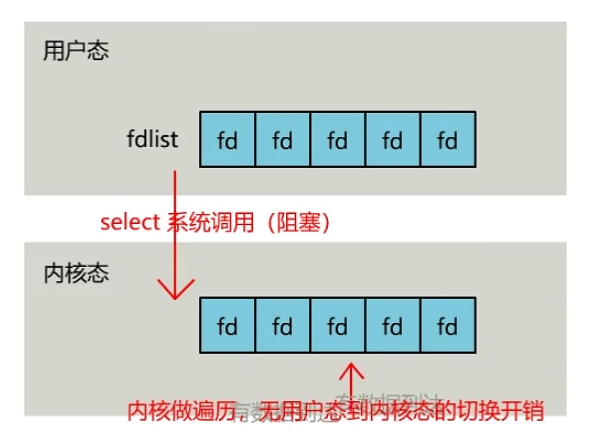
select问题:
【1】牵扯到集合的拷贝。
【2】能监听端口的数量有限,单个进程所能打开的最大连接数有FD_SETSIZE宏定义。
【3】需要遍历收集事件可操作。
poll
poll与select比较相似,只是描述fd集合的方式不同,有一个pollfd结构,就解决了select的问题。
struct pollfd {
int fd; /*文件描述符*/
short events; /*监控的事件*/
short revents; /*监控事件中满足条件返回的事件*/
};
select,poll每次调用都要把fd集合从用户态往内核态拷贝一次
epoll
不会随着fd数目增长降低效率,select轮询。
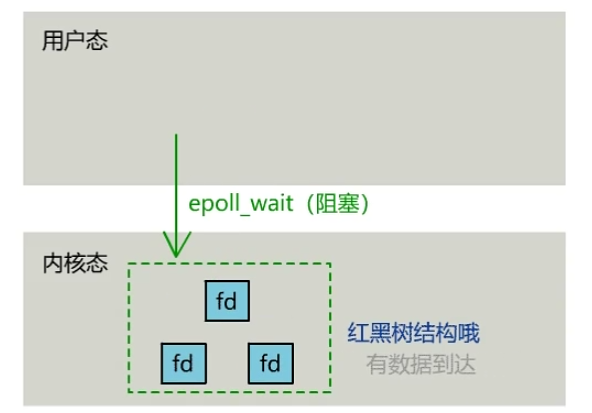
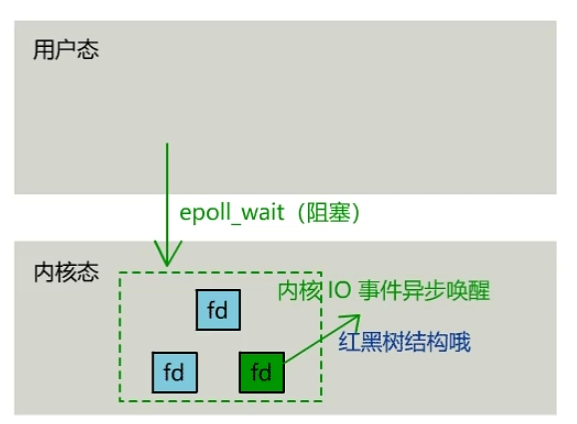
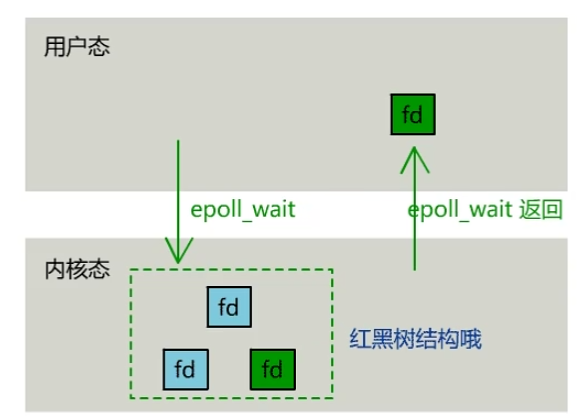
- rbr: 红黑树。为了支持对海量连接的高效查找、插入和删除,eventpoll 内部使用的就是红黑树。通过红黑树来管理用户主进程accept添加进来的所有 socket 连接。
- rdllist: 就绪的描述符链表。当有连接就绪的时候,内核会把就绪的连接放到 rdllist 链表里。这样应用进程只需要判断链表就能找出就绪进程,而不用去遍历红黑树的所有节点了。
对比
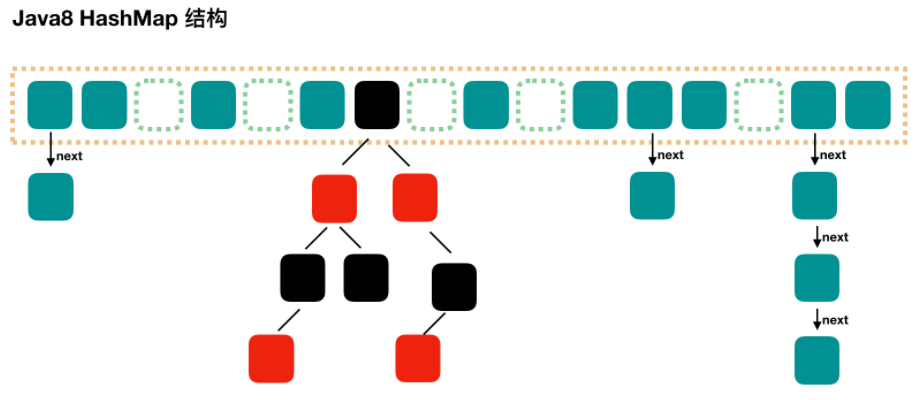
hashmap扩容、concurrentHashmap
hash
相同的对象多次输入得到相同的值,不同的输入大概率得到不同的值。如MD5, SHA系列。
JDK8扩容机制
空参构造函数:实例化的Hashmap内部数组为null,没有实例化,第一次调用put方法时,会第一次初始化扩容为16.
有参构造函数:用于指定容量,会找到不小于指定容量的2的幂数,设为容量,阈值=容量x负载因子。
扩容是容量和阈值都变为原来的两倍。
HashMap初始化后首次插入数据时,先发生resize扩容再插入数据,之后每当插入的数据个数达到threshold时就会发生resize,此时是先插入数据再resize。
结点hash后取余,要么在原位置,要么在原位置+原容量。因为扩容是二倍。因此,在扩容时,不需要重新计算元素的hash了,只需要判断最高位是1还是0就好了。
扩容:创建一个数组,把结点复制过去。老位置置为null,方便GC
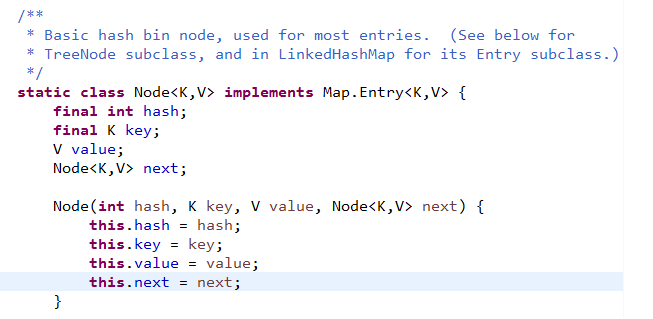
static final int TREEIFY_THRESHOLD = 8;
/**
* The bin count threshold for untreeifying a (split) bin during a
* resize operation. Should be less than TREEIFY_THRESHOLD, and at
* most 6 to mesh with shrinkage detection under removal.
*/
static final int UNTREEIFY_THRESHOLD = 6;
在扩容完成之后,如果某个节点的是树,同时现在该节点的个数又小于等于6个了,则会将该树转为链表。
* 0: 0.60653066
* 1: 0.30326533
* 2: 0.07581633
* 3: 0.01263606
* 4: 0.00157952
* 5: 0.00015795
* 6: 0.00001316
* 7: 0.00000094
* 8: 0.00000006
红黑树空间比较大,为了空间和时间的权衡,看链表达到8个的概率已经非常非常小。
concurrentHashmap
CAS + synchronized 实现
size问题
JDK1.7中,会使用不加锁的方式尝试计算
JDK1.8:
// 两种情况
// 1. counterCells 数组未初始化,在没有线程争用时,将 size 的变化写入此字段
// 2. 初始化 counterCells 数组时,没有获取到 cellsBusy 锁,会再次尝试将 size 的变化写入此字段
private transient volatile long baseCount;
// 用于同步 counterCells 数组结构修改的乐观锁资源
private transient volatile int cellsBusy;
// counterCells 数组一旦初始化,size 的变化将不再尝试写入 baseCount
// 可以将 size 的变化写入数组中的任意元素
// 可扩容,数组的最大容量就是CPU的核数
private transient volatile CounterCell[] counterCells;
counterCells:这是一个数组,里面放着CounterCell对象,这个类里面就一个属性,其使用方法是,在高并发的时候,多个线程都要进行计数,每个线程有一个探针hash值,通过这个hash值定位到数组桶的位置,如果这个位置有值就通过CAS修改CounterCell的value(如果修改失败,就换一个再试),如果没有,就创建一个CounterCell对象。
size()调用链:
public int size() {
long n = sumCount();
return ((n < 0L) ? 0 :
(n > (long)Integer.MAX_VALUE) ? Integer.MAX_VALUE :
(int)n); // 将 n 裁剪到 [0, Integer.MAX_VALUE] 内
}
final long sumCount() {
CounterCell[] as = counterCells; CounterCell a;
long sum = baseCount;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}
map 中键值对的个数通过求 baseCount 与 counterCells 非空元素的和得到。何时计算?concurrenthashmap内部改变键值对个数的方法都会调用addCount方法更新键值对个数。
// x表示元素变化个数
private final void addCount(long x, int check) {
CounterCell[] as; long b, s;
// 如果空就直接cas加到baseCount中
if ((as = counterCells) != null ||
!U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) {
// counterCells非空或者cas失败
CounterCell a; long v; int m;
boolean uncontended = true;
//第一个条件as == null成立说明,counterCells数组没有创建,
//而且通过CAS修改baseCount失败,说明有别的线程竞争CAS
//a = as[ThreadLocalRandom.getProbe() & m]) == null,
//说明数组是创建了,但是通过探针hash定位的桶中没有对象
//如果有对象,执行最后一个,进行CAS修改CounterCell对象,如果也失败了,就要进入下面的方法
if (as == null || (m = as.length - 1) < 0 ||
(a = as[ThreadLocalRandom.getProbe() & m]) == null ||
!(uncontended =
U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) {
fullAddCount(x, uncontended);
return;
}
if (check <= 1)
return;
// 如果 check 大于 1,则计算当前 map 的 size,为判断是否需要扩容做准备
s = sumCount();
}
if (check >= 0) {
Node<K,V>[] tab, nt; int n, sc;
while (s >= (long)(sc = sizeCtl) && (tab = table) != null &&
(n = tab.length) < MAXIMUM_CAPACITY) {
int rs = resizeStamp(n);
if (sc < 0) {
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0)
break;
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
transfer(tab, nt);
}
else if (U.compareAndSwapInt(this, SIZECTL, sc,
(rs << RESIZE_STAMP_SHIFT) + 2))
transfer(tab, null);
s = sumCount();
}
}
}
counterCells 数组未初始化 a. CAS 一次 baseCount b. 如果 CAS 失败,则调用 fullAddCount 方法
counterCells 数组已初始化 a. CAS 一次当前线程探针哈希到的数组元素 b. 如果 CAS 失败,则调用 fullAddCount 方法
private final void fullAddCount(long x, boolean wasUncontended) {
int h;
if ((h = ThreadLocalRandom.getProbe()) == 0) {\
//如果为0,就初始化,这里其实就是把种子和随机数设置到(Thread)线程中
ThreadLocalRandom.localInit(); // force initialization
h = ThreadLocalRandom.getProbe();
wasUncontended = true;
}
boolean collide = false; // True if last slot nonempty
for (;;) {
CounterCell[] as; CounterCell a; int n; long v;
if ((as = counterCells) != null && (n = as.length) > 0) {
if ((a = as[(n - 1) & h]) == null) {
if (cellsBusy == 0) { // Try to attach new Cell
CounterCell r = new CounterCell(x); // Optimistic create
if (cellsBusy == 0 &&
U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) {
boolean created = false;
try { // Recheck under lock
CounterCell[] rs; int m, j;
if ((rs = counterCells) != null &&
(m = rs.length) > 0 &&
rs[j = (m - 1) & h] == null) {
rs[j] = r;
created = true;
}
} finally {
cellsBusy = 0;
}
if (created)
break;
continue; // Slot is now non-empty
}
}
collide = false;
}
else if (!wasUncontended) // CAS already known to fail
wasUncontended = true; // Continue after rehash
else if (U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))
break;
else if (counterCells != as || n >= NCPU)
collide = false; // At max size or stale
else if (!collide)
collide = true;
else if (cellsBusy == 0 &&
U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) {
try {
if (counterCells == as) {// Expand table unless stale
CounterCell[] rs = new CounterCell[n << 1];
for (int i = 0; i < n; ++i)
rs[i] = as[i];
counterCells = rs;
}
} finally {
cellsBusy = 0;
}
collide = false;
continue; // Retry with expanded table
}
h = ThreadLocalRandom.advanceProbe(h);
}
else if (cellsBusy == 0 && counterCells == as &&
U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) {
boolean init = false;
try { // Initialize table
if (counterCells == as) {
CounterCell[] rs = new CounterCell[2];
rs[h & 1] = new CounterCell(x);
counterCells = rs;
init = true;
}
} finally {
cellsBusy = 0;
}
if (init)
break;
}
else if (U.compareAndSwapLong(this, BASECOUNT, v = baseCount, v + x))
break; // Fall back on using base
}
}
fullAddCount功能:
- counterCells 数组的初始化和扩容。
- counterCells 元素的初始化。
- 将 size 的变化,写入 counterCells 中的某一个元素。
总结:思想尽量降低线程冲突,以最快速度写入size变化。如果没有冲突,size变化写入baseCount,一旦发生冲突,就用一个数组(counterCells)来存储后续所有 size 的变化,counterCells最大为CPU核数,随机设置数组某个位置,失败就下个位置,成功为止。这样,线程只要对任意一个数组元素写入 size 变化成功即可。
put操作
private transient volatile int sizeCtl;
- 负数代表正在进行初始化或扩容操作
- -1代表正在初始化
- -N 表示,这个高16位表示当前扩容的标志,每次扩容都会生成一个不一样的标志,低16位表示参与扩容的线程数量
- 正数或0,0代表hash表还没有被初始化,正数表示达到这个值需要扩容,其实就等于(容量 * 负载因子)
如果通过hash值定位到桶的位置为null,直接通过CAS插入
如果发现节点的Hash值为MOVED,协助扩容,
整体流程:
- 数组没有初始化就先初始化数组
- 计算当前插入的key的hash值
- 根据第二步的hash值定位到桶的位置,如果为null,直接CAS自旋插入
- 如果是链表就遍历链表,有相同的key就替换,没有就插入到链表尾部
- 如果是红黑树直接插入
- 判断链表长度是否超过8,超过就转为红黑树
- ConcurrentHashMap元素个数加1
扩容操作
扩容的时候需要把旧数组的数据拷贝到新数组,当某个桶中的数据被拷贝完成之后,就把旧数组的该桶标记为ForwardingNode,当别的线程访问到这个桶,发现被标记为ForwardingNode就知道该桶已经被copy到了新数组,之后就可以根据这个做相应的处理。
总结一下流程:按桶分
- 判断是否需要扩容
- 如果正在扩容中,就协助扩容
- 如果还没有扩容,新建数组开始扩容
synchronized升级
大部分情况,不存在多线程竞争,并且总是由一个线程多次获得,为了让其获得锁的代价更低,引入了偏向锁。在对象头存储当前线程ID。假如该锁没有被其他线程所获取,没有其他线程来竞争该锁,那么持有偏向锁的线程将永远不需要进行同步操作。
偏向锁不存在释放概念。
线程来了,无锁,也就是可偏向状态,把线程ID写入对象头。
a)cas成功,获得了偏向锁,接着执行同步代码块。
b)失败,其它线程获得了偏向锁,说明存在竞争,需要等到安全点,也就是没有线程在执行的时候,升级为轻量级锁。
线程来了,有锁,偏向状态,检查线程ID,相等继续,不等升级为轻量级锁。
偏向锁怎么升级为轻量级锁?
如果不一致(其他线程,如线程2要竞争锁对象,而偏向锁不会主动释放因此还是存储的线程1的threadID),那么需要查看Java对象头中记录的线程1是否存活,如果没有存活,那么锁对象被重置为无锁状态,其它线程(线程2)可以竞争将其设置为偏向锁;如果存活,那么立刻查找该线程(线程1)的栈帧信息,如果还是需要继续持有这个锁对象,那么暂停当前线程1,撤销偏向锁,升级为轻量级锁,如果线程1 不再使用该锁对象,那么将锁对象状态设为无锁状态,重新偏向新的线程。
轻量级锁
主要是自旋锁,轻量级锁适用于那些同步代码块执行的很快的场景,这样,线程原地等待很短很短的时间就能够获得锁了。基于这个问题,我们必须给线程空循环设置一个次数,当线程超过了这个次数,我们就认为,继续使用自旋锁就不适合了,此时锁会再次膨胀,升级为重量级锁。
在代码访问同步资源时,如果锁对象处于无锁不可偏向状态,jvm首先将在当前线程的栈帧中创建一条锁记录(lock record),用于存放:
displaced mark word(置换标记字):存放锁对象当前的mark word的拷贝owner指针:指向当前的锁对象的指针,在拷贝mark word阶段暂时不会处理它
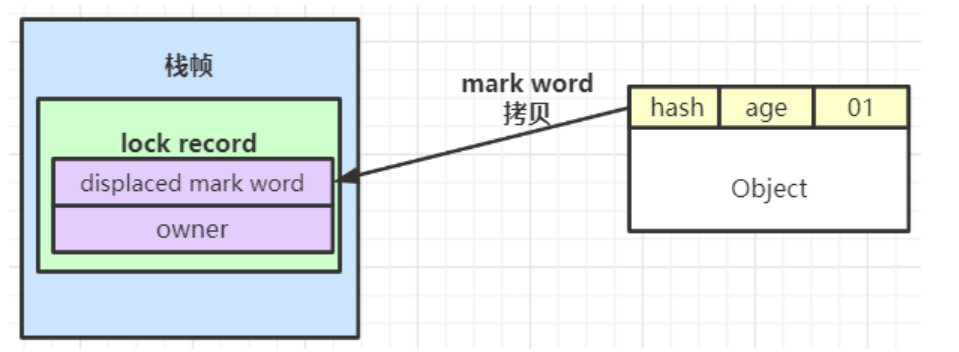
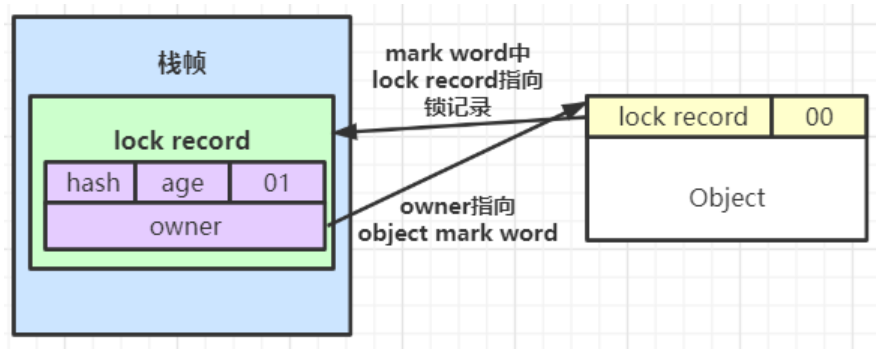
- 如果CAS替换失败,则判断当前对象的mark word是否指向当前线程的栈帧:
- 如果是则表示当前线程已经持有对象的锁,执行的是
synchronized的锁重入过程,可以直接执行同步代码块 - 否则说明该其他线程已经持有了该对象的锁,如果在自旋一定次数后仍未获得锁,那么轻量级锁需要升级为重量级锁,将锁标志位变成
10,后面等待的线程将会进入阻塞状态
- 如果是则表示当前线程已经持有对象的锁,执行的是
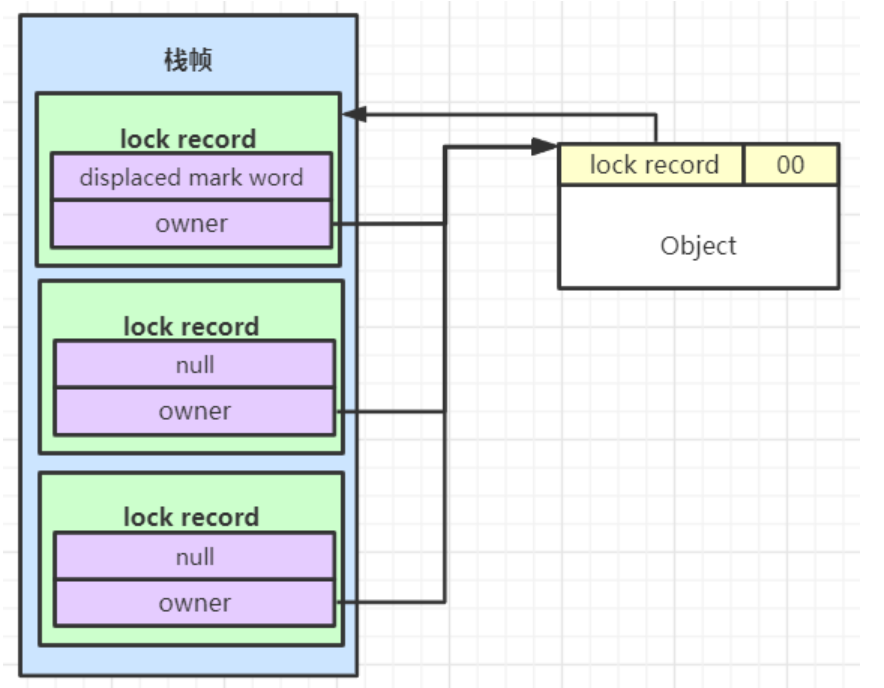
如三次重入:
重量级锁
但是阻塞或者唤醒一个线程时,都需要操作系统来帮忙,这就需要从用户态转换到内核态,而转换状态是需要消耗很多时间。
重量级锁是依赖对象内部的monitor(监视器/管程)来实现的 ,而monitor 又依赖于操作系统底层的Mutex Lock(互斥锁)实现。
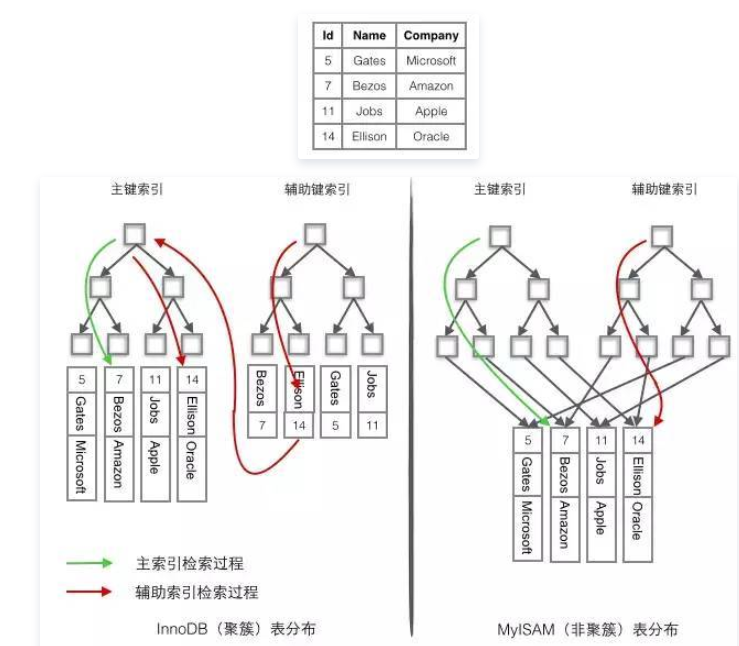
mysql索引B+树
聚簇索引:数据存储和索引放在了一块,索引的叶子结点保留了行数据。
非聚簇索引:索引的叶子结点指向了数据对应的位置。
非主键索引存储的是索引列的数据和主键的值。把这种叶子节点不存储表数据的索引叫做二级索引
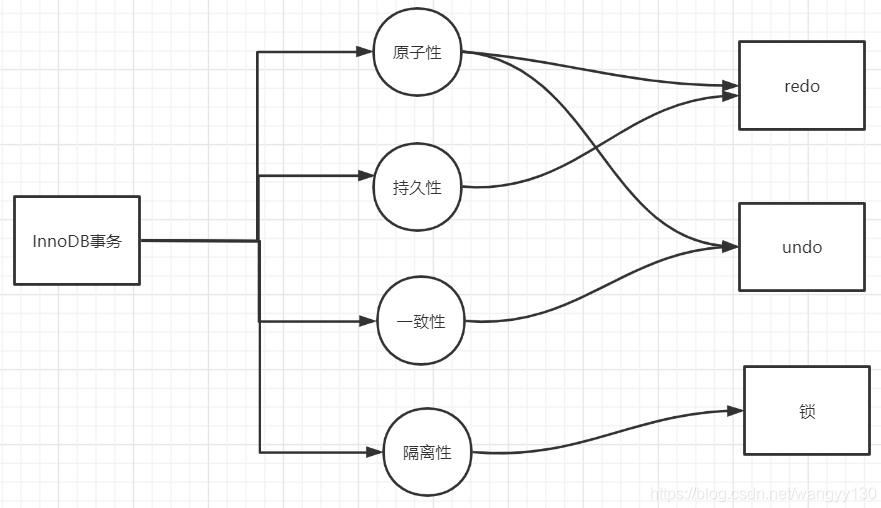
mysql ACID分别怎么保证
redo log重做日志,通常是物理日志,幂等,记录页的物理修改操作,一部分是内存中的日志缓重,一部分是重做日志文件。在事务进行时,Innodb首先将重做日志信息先放入重做日志缓冲中,然后按照一定频率将其刷新到重做日志文件中。
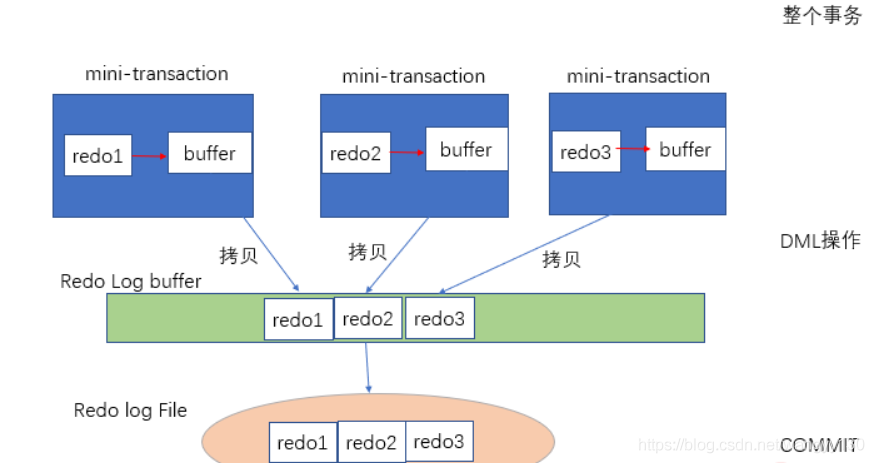
undo段位于共享表空间内。undo是逻辑日志,因此只是将数据库逻辑的恢复到原来的样子。
事务提交后并不能马上删除undo log 以及undo log所在的页。这是因为可能还有其他事务需要通过undo log来得到行记录之前的版本。故事务提交时将undo log放入一个链表中,是否可以删除undo log及undo log所在的页由purge线程来判断。
重做日志是如何保证持久性的?
为了确保每次日志都写入重做日志文件,在每次将重做日志缓冲写入重做日志文件后,innodb存储引擎都需要调用一次fsync操作,通过fsync来确保日志总能被持久化到磁盘中。同时,重做日志文件的持久化操作是在数据库数据持久化操作之前已经完成的。
原子性
commit后宕机,有redo log恢复。
正常情况,undo log,事务回滚。
一致性
我给你三百,我少三百,你多三百。当事务执行时发生宕机或者异常时,通过回滚执行undo log能使数据返回初始状态来保证数据一致性。
隔离性
解决的是并发事务的问题。
四个隔离级别
READ UNCOMMITTED : 可以读取事务未提交的数据。
READ COMMITTED : 只能读取已经提交事务的数据。
REPEATABLE READ: RR 可重复读。事务在执行过程中看到的值和事务开始时的值是一样的。
SERIALIZABLE : SR 序列化。所有事务按照次序依次执行。当一个事务开始未提交时,其他事务均不能执行。
mysql MVCC机制快照读、当前读,何时改变
当前读:读取的是最新版本,像UPDATE、DELETE、INSERT、SELECT ... LOCK IN SHARE MODE、SELECT ... FOR UPDATE这些操作都是一种当前读,为什么叫当前读?就是它读取的是记录的最新版本,读取时还要保证其他并发事务不能修改当前记录,会对读取的记录进行加锁。
快照读。
begin;
#假设users表为空,下面查出来的数据为空
select * from users; #没有加锁
#此时另一个事务提交了,且插入了一条id=1的数据
select * from users; #读快照,查出来的数据为空
update users set name='mysql' where id=1;#update是当前读,所以更新成功,并生成一个更新的快照
select * from users; #读快照,查出来id为1的一条记录,因为MVCC可以查到当前事务生成的快照
commit;
可以看到前后查出来的数据行不一致,发生了幻读。所以说只有MVCC是不能解决幻读问题的,解决幻读问题靠的是间隙锁。
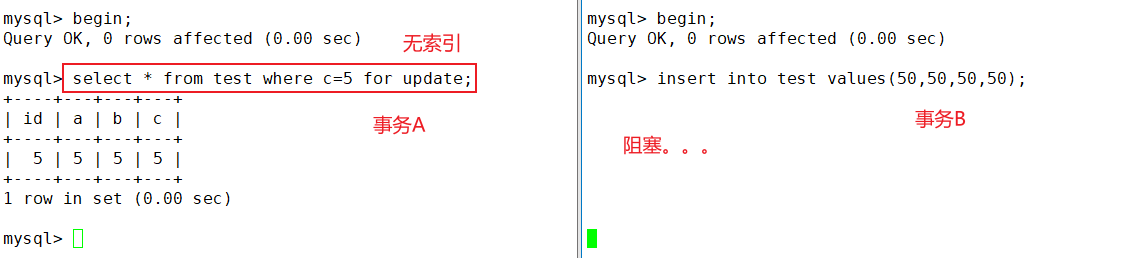
RR级别下,无索引的条件字段的当前读会把每条记录都加上排他锁,还有间隙锁。所以,当前读或者插入、更新、删除操作要加上索引。
select * from test where b = 10 for update;
# b为普通索引
b=10的记录加行锁。上下两条间隙加间隙锁。锁住的应当为(5,20)。这个范围内的操作会阻塞。
思维题
还以为是脑筋急转弯,是看里面的编程思想的,如递归。
(1)两个人轮流扔硬币,谁先扔正面谁赢,输了就给对方扔,扔到正就停。求先抛的人赢得概率。
第一次扔赢:0.5(A正)
第二次赢:0.5x0.5x0.5(A反B反A正)
第三次赢:1/2^(2n-1)
回溯CNK问题,没写出来。
我原来是个笨蛋啊。
package cn.orzlinux.nettysource;
import java.util.*;
class Solution {
Deque<Integer> deque = new LinkedList<>();
List<List<Integer>> result = new LinkedList<>();
public List<List<Integer>> combine(int n, int k) {
combine0(n,k,1);
return result;
}
private void combine0(int n,int k,int start) {
if(deque.size()==k) {
result.add(new LinkedList<>(deque));
}
for(int i=start;i<=n;i++) {
deque.addLast(i);
combine0(n,k,i+1);
deque.pollLast();
}
}
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
int n = scanner.nextInt();
int k = scanner.nextInt();
scanner.close();
System.out.println((new Solution()).combine(n,k));
}
}