6.824分布式笔记2-VMware_FT、Raft
VMware FT
VMware fault tolerance.
就是虚拟机那个VMware。
VMware FT需要两个物理机,将primary和backup运行在一台机器的两台虚拟机无意义,不能抵御硬件故障。
状态转移和复制状态机
想让服务器上两个副本保持同步。
状态转移:state transfer,primary将状态,比如内存里的内容,拷贝并发送给backup。
复制状态机:replicated state machine,发送事件,如果是一些不确定的随机事件,如随机数或者和时间有关的,primary执行完之后再将确切的数据发送给baskup。
通信
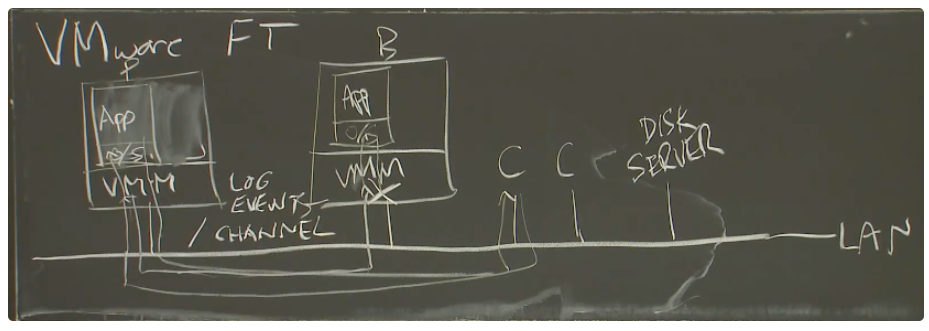
左边是P,Primary,右边是B,Backup,C是Client,Disk SERVER是远程磁盘(P和B只关注内存上的东西),这些东西运行在一个LAN上。
Primary和Backup之间有交互、心跳。P和B不一样会出现问题:如chunk服务器那个过期时间,如果P和B不一致,可能会出现两个primary chunk。
GFS里面追加文件时,会找现有的primary chunk或者选一个primary chunk,其他作为secondary trunk。如果出现两个primary chunk,他们不知道彼此的存在,但是都能和客户端通信——从而导致不同的数据拷贝,称为脑裂。所以就算是联系不到primary了,也要等待过期时间,可能只是网络不好,但是primary还活着。
C给primary发数据包,primary所在的物理机收到之后,产生一个中断,并将这个中断发送给VMM(Virtual Machune Monitor,用于在硬件上模拟虚拟机),VMM发现是给多副本的输入,然后在虚拟机上模拟数据包到达的中断,primary get,然后vmm将网络数据拷贝一份,发送给backup所在虚拟机的vmm。primary的回复报文通过vmm模拟的虚拟网卡发送给客户端,backup所在vmm会丢弃回复报文。
非确定性事件
- 客户输入。网络数据包有两部分内容,一个是数据,一个是中断,在primary和backup中断的时间,位置,如果不同的话,可能会使他们的状态产生误差。
- 一些在不同计算机上行为不同的指令:如随机数、获取当前时间、计算机ID
- 多CPU的并发,例如抢占锁,由于细微的时间差别,在Primary上,核1得到了锁,在Backup上,核2得到了锁,两个副本就会出现区别。硬件现在一般都是多核CPU,但是VMM暴露给Primary和Backup的虚拟机的硬件是单核的。
控制输出
前面提到Backup是不会返回输出给客户端或者Primary的,所以就可能出现数据不同步情况:
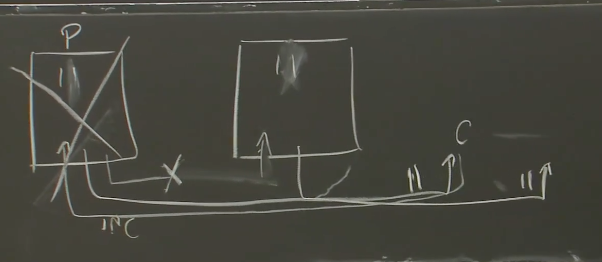
P和B原本都是10,客户端要服务器自增,变成11,P完成了,返回给客户端,但是返回之后没来得及和Backup交互,立刻就挂了,之后B备份启动作为Primary,自增,还是11,问题出现。
解决:P发送给客户端之前,要等待B接收到log event信息,并返回一个ACK,确保B已经知道了这个事件,P才能返回给C。这样可能会造成额外的延时,因为要等待B的确认。
之前还在奇怪为啥不在应用层直接传递消息,这个针对的是底层的复制,二者不一样。这里的复制行为:结合硬件支持,例如P每秒定时中断100次,P每次中断都会发送Log给B,B的VMM内存里有缓冲区缓存从P接收到的指令,B不允许领先P,只有在缓冲区有东西时才会执行。
重复输出
情形:客户端发起了一个自增操作请求,P自增之后(假设10自增变为11),P发送log给B了,然后给客户端发送消息之后,P崩溃了,B作为接盘侠,接管服务,首先要消耗VMM的log缓冲区,以便和原来的P保持同步,然后才能接收客户端的请求,但是B又会往客户端发送11,因为此时B已经接管了服务(也不能保证P给客户端发送了,B不知道),从客户端角度讲,就会造成消息重复输出,这与我们所想的理想状态相悖(从客户端看,就像和单机交互)。
解决方法是:不需要额外解决,客户端一般通过TCP和服务进行交互,B接管之后,TCP连接的状态和TCP传输的序列号都是一致的,发送的时候就会是一个重复的报文,会在TCP层面被丢弃。如果不是TCP,就需要其他机制,例如序列号。
这里面同样有相当多的细节,后面的lab会遇到的。
Test and Set
前面说的一直都是假设出现的是fail-stop故障(出错以后会单纯地停止运行,如插头被人拔了)。实际情况中,可能会是其他问题,如Primary和Backup都在运行,但是他们之间网络不好。就会以为对方挂了,要接管服务,就乱了。
解决:第三方:Test and Set服务,来决定Primary还是Backup上线。
Test and Set服务不和P、B运行在一台物理机上,需要网络。当你发送一个test and set请求,这个服务就会在内存里设置标志位,并返回旧值。相当于一个锁。
但是P请求了test and set,然后啪的一下挂了,B再请求请求不到了咋办?
理一下:如果其中一个挂了,另一个去请求,得到了,就是了;如果两个都活着,但是以为对方挂了,只有一个能获取到锁。服务上线之后,应该有个类似解锁的操作,以便下次请求。
Raft
脑裂 Split Brain
之前的几个东西,虽然是容错系统,都依赖于单节点。
- MapReduce,依赖于Master节点。
- GFS,依赖于一个单节点确定每一份数据的Primary chunk的位置。
- VMware FT,依赖于Test-and-Set服务来在故障的时候恢复虚拟机接管。
单点故障,Single Point of Failure。
这不套娃吗,要不想这个单点故障,做成Master或者test and set容错,但是又进一步需要一个单节点。
如果单纯的加机器,S1和S2之间没有协调机制的话,还存在脑裂问题。如果C1要请求一个就行了,脑裂;如果C2要请求两个才可以,没有容错。

如果多副本系统要排除脑裂的可能:
- 构建一个不可能出现故障的网络。
- 默认等待两个服务器响应,如果只有一个响应,找运维人员。
Majority Vote
构建能自动恢复,同时避免脑裂的多副本系统时,关键在于Majority Vote。
服务器数量要是奇数,不然的话,如果服务器之间的通信出现了故障,另外两部分看起来完全一样,脑裂。
Raft的Leader选举,比如提交一个Log条目,不行凑够过半的服务器批准才可以。这样就算出现了网络分区,也只有一个能凑够过半的服务器。
过半是相对于服务器的总数而言(包括开机和故障)
如果系统有 2 * F + 1 个服务器,那么系统最多可以接受F个服务器出现故障,仍然可以正常工作。
核心就是:过半数量才能执行操作。
比如Raft 的Leader选举,一个Leader竞选成功,一定超过了半数服务器投票,新的Leader必然知道旧Leader的term number和所有操作,(过半、过半必然有重叠)。
Raft初探
Raft以Library的形式存在于服务中,一个基于Raft的多副本服务,每个服务的副本由:应用程序代码和Raft库 组成。应用程序代码接收RPC或者客户端请求,不同节点之间Raft库互相合作,维护多副本之间的操作同步。
Raft会记录操作的日志。
流程示例:

C是客户端,要使用kv服务,客户端角度看,就是和单点服务在交互。
客户端会把请求发送给当前Raft集群中的Leader节点对应的应用程序,用户级别的请求,比如访问kv数据库的请求,put、get。
应用程序会将请求向下发送到Raft层。Raft记录操作,并在Raft节点之间交互直到过半的Raft节点将这个操作加入日志,给上层应用程序发送通知:已经在Raft之间提交了副本,可以真正执行操作了。然后日志里面的请求同步到上层kv应用程序。
有疑问,过半就行的话,有些节点可能并没有某些记录,它们作为Leader节点之后不会遗漏数据吗?
同步时序
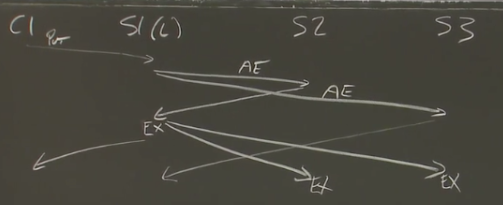
客户端向作为Leader的S1发送一条put请求,S1收到之后,会发送一个添加日志(AppendEntries)的RPC到其他的副本,等待它们的响应,只要超过半数的结点响应了(包括Leader),就可以了。如果有三个节点的话,就是一个响应就可以了,无需等待其他的响应,Leader执行请求,返回给客户端。然后通知所有的节点,这个请求已经被Leader commit了,这个通知可选择额外通知,或者在下一条AE的时候附带上。
卧槽,我的疑问可太多了,并发请求?每个节点的日志顺序怎么保证?全部阻塞在一条请求吗?超过半数就行万一有一个压根没收到AE,和其他结点的Log不一样,后面要怎么处理?。。。继续看先。
Raft Log
Raft的日志比较中药,其中一个原因是:Log是Leader用来排序操作的一种手段。
一堆客户端请求同时到达后,Leader必须对这些请求确定一个顺序,并且保证其他副本都遵从这个顺序,如数字编号。
Log缓存:对于非Leader副本,操作需要先暂存,直到受到了Leader的commit确认;Leader节点缓存操作,以便同步给因为网络等原因丢失消息的Follower;Follwer故障重启可以有个依据,但是重启之后并不知道log中的条目有没有被提交。【问题】
应用层接口
应用程序和Raft之间主要有两个接口:
- 应用层转发客户端请求的接口。
- Raft通知应用层可以commit了的接口。
Raft会最终强制不同副本的log保持一致。
先熟悉下论文吧
为什么要多台计算机保存同一份数据:随着分布式系统节点数量增加,故障频繁,需要备份。
从多台计算机读取这个数据时一样吗:为了解决这个问题,就有了各种各样的副本控制协议。
中心化副本控制协议
副本的更新由一个中心节点协调。一些分布式存储会采用这个,如GFS。
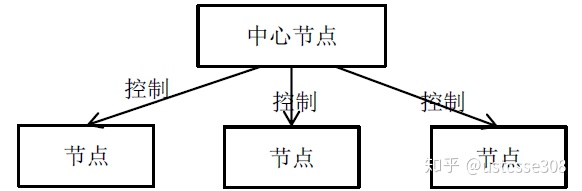
去中心化:没有中心节点,节点平等。大家都可以接受心情求,协商达成数据的一致。比较复杂。
主从节点数据更新流程:
主节点提供写入操作,数据同步到其他节点。
数据同步的方式分为同步和异步。
同步,可靠性好,但是可用性差,延迟大:
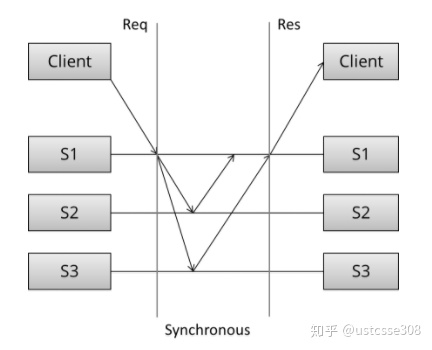
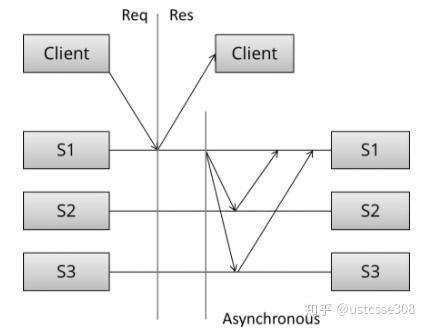
异步,一个节点完成就立刻返回,然后后台同步数据,吞吐量好,但是存在数据丢失可能,客户得到响应后立刻访问可能得到旧数据:
数据的流向可以分为链式和主从:
链式指从一个节点推送到最近的节点(最近可以用ip或者心跳ttl来衡量)。
主从模式:
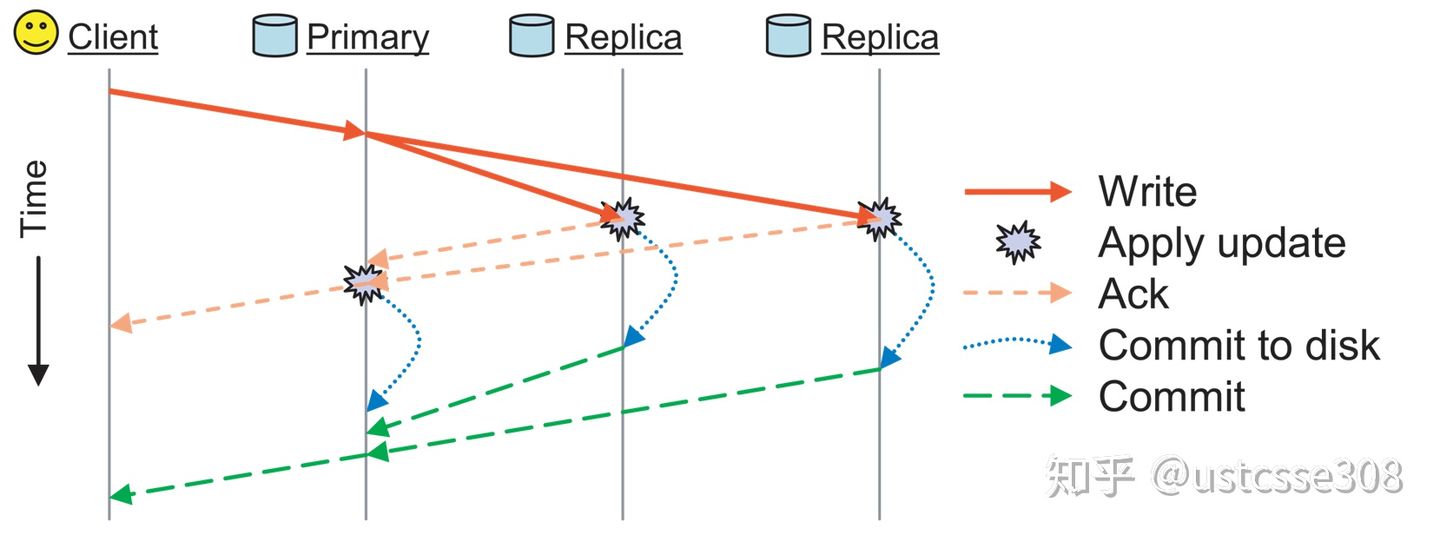
主从节点数据读取:
看要求,如果读到过期数据也无所谓,就可,否则不行。
Raft:
Reliable, Replicated, Redundant, And Fault-Tolerant
raft 协议解决CAP中CP问题,consistency, availability, partition tolerance。
一致性:要么读取失败,要么读到最新的数据。强调数据正确。
可用性:一部分节点故障后,整体还能响应客户端的读写请求。
分区容忍性:网络故障时,分区的两边的处理都可以继续,就是分区容忍的。必选。
网络分区:分布式系统中,不同的节点分布在不同的子网络。可能由于网络问题,出现了不联通的孤立区域。

CA: 将所有数据放在一个分布式节点上。
CP:如果要求数据是强一致的,网络分区会导致同步时间可能会很大,可用性就得不到保障(不同步好这个数据,所有客户端都别想看到)。
AP:要求可用性,数据不一致,至少能用。这里放弃的是数据的强一致性,保留数据的最终一致性。
~Raft是CP问题。~~不确定:感觉有点像CP,但是为了保障可用性,把强一致性那个同步改成了半数以上同步,又有点AP的感觉。
raft主要做的就是:问题分解和状态简化。
将【复制集中节点一致性】这个复杂问题简化为可以被独立解释、理解、解决的子问题。例如leader election, log replication, safety, membership changes。
状态简化就是对算法做出一些限制,减少要考虑的状态数,减少不确定性。例如:保证新选举的leader会包含所有commited log entry。
raft协议里,一个节点会处于三个状态之一:leader、follower、candidate。
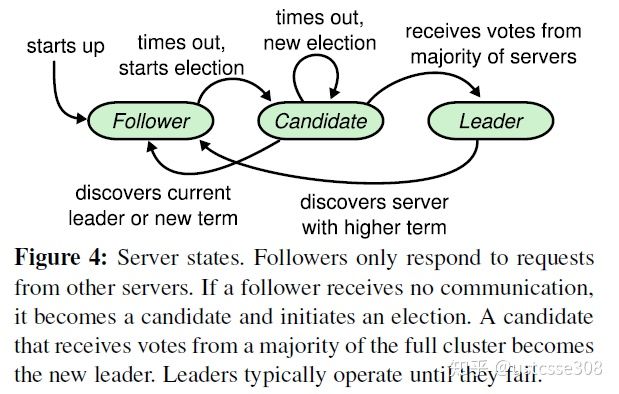
所有节点启动时都是follower状态;在一段时间内如果没有收到来自leader的心跳,从follower切换到candidate,发起选举;如果收到majority的造成票(含自己的一票)则切换到leader状态;如果发现其他节点比自己更新,则主动切换到follower。
一个系统最多只有一个leader,leader会给follower发心跳,表明自己的存活状态。
任期:term,以election开始,然后是一段或长或短的稳定工作期。
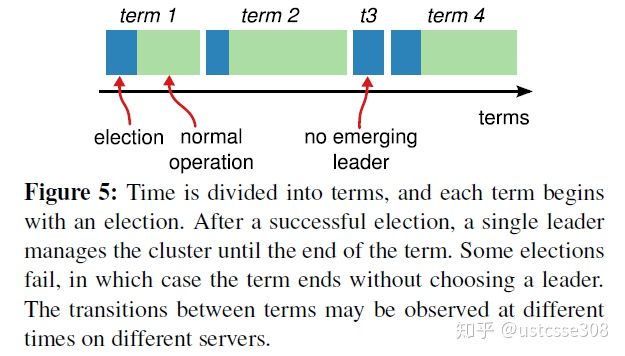
选举过程详解:
如果follower在election timeout内没有收到leader的心跳,会主动发起选举。此时,可能是leader挂了,也可能是follower和leader网络故障。
为了避免无意义选举,如一些follower连不上leader,不断发起选举,任期号不断增加,扰乱集群。要有prevote,节点在开始选举前,要和其他所有节点通信,超过半数以上相应才开始选举。
增加节点本地的current term,切换到candidate,投自己一票,并行给其他节点发送RequestVote RPCs,等待其他节点的回复。
可能出现的结果:
- 收到majority的投票,win election,成为leader。新leader会给所有节点发消息,避免其他节点发起新的选举。
- 被人当选,切换回follower。
- 一段时间没有收到majority投票,保持candidate状态,重新发出选举。
投票者的约束:
- 一个任期内只能投一票
- 候选人知道的信息不能比自己少
- 先到先得
当没有候选人赢得过半票数,选举无效了,这时需要等待一个随机时间间隔,也就是说,等待选举超时的时间间隔,是随机的。
log replication:
leader在发送log时,只需要大多数节点的回复就行了,所以可能出现的log状态为:
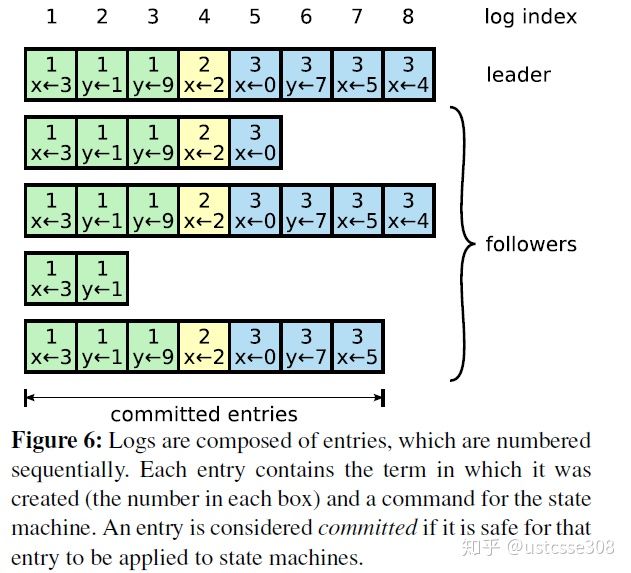
log由顺序编号的log entry组成,每个log entry包含command,还有产生这个log entry的leader term。raft为了保证高可用,不是强一致性,而是最终一致性。leader会不断尝试给follower发log entries,直到所有的log entries都相同。
safety:
衡量一个分布式算法的属性:
- safety: nothing bad happens
- Liveness: something good eventually happens
raft保证被复制到大多数节点的日志不会被回滚,就是safety属性。而raft最终会让所有节点状态一致,liveness属性。
raft协议会保证的属性:
Election safety: 一个term最多只有一个leader。
Leader append only: leader不会覆写或者删除log,只会添加新的entries。
Log matching: 如果两个日志包含有相同index和term的entry,在给定索引之前的所有条目中,日志都是相同的。leader在AppendEntries中包含最新log entry之前的一个log 的term和index,如果follower在对应的term index找不到日志,那么就会告知leader不一致。
log match 可能会出现的问题:框里的数字代表哪个任期的entry。下图leader是term8
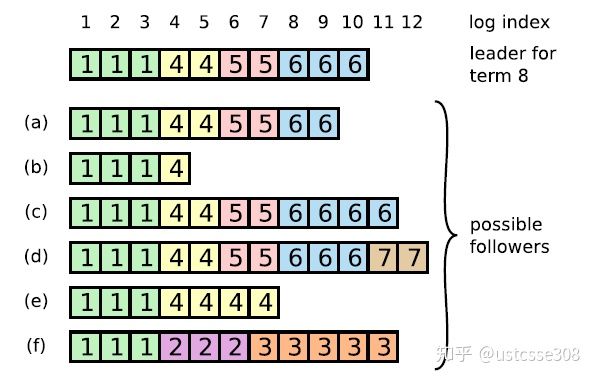
follower比leader日志少:可能网络故障follower节点没收到leader发出的appendEntry的消息。
follower比leader日志多:可能这个follower之前当过leader,但是还没把命令发出去就挂了,所以只有它自己有这个entry。
像ef这样的,是曾经当选过entry,收到过一些请求,但是还没发出appendEntry就挂了。一直挂到term8才恢复过来。
哟西,我之前有疑问的就是这种情况,下面看看咋解决的。
当出现了leader与follower不一致的情况,leader会强制follower复制自己的log。
Leader会维护一个nextIndex[]数组,记录了Leader可以发送给每一个follower的log index,初始化为Leader最后一个log index+1,详细流程:
- Leader初始化数nextIndex数组
- AppendEntries里prevLogTerm和prevLogIndex来自于logs[nextIndex[x]-1]。(仔细分析一下就明白了)
- 如果follower判断添加的位置之前的log term不等于prevLogTerm,返回false。
- Leader收到follower的回复,如果是False,则nextIndex[x]-=1,跳转到第二步继续判断。
- 同步nextIndex[x]之后的所有log entries。
Leader completeness:对于给定的term, 如果一个log entry被提交了,那这个entry对于更新term的leader就是可见的。
State Machine Safety: 如果一个服务器以一个index执行了log entry到状态机上,其他的server不会在index上执行别的entry。
corner case 不常见的情况
stale leader
网络分区(network partition)的情况下,可能会出现两个Leader,但是两个Leader的任期是不同的。
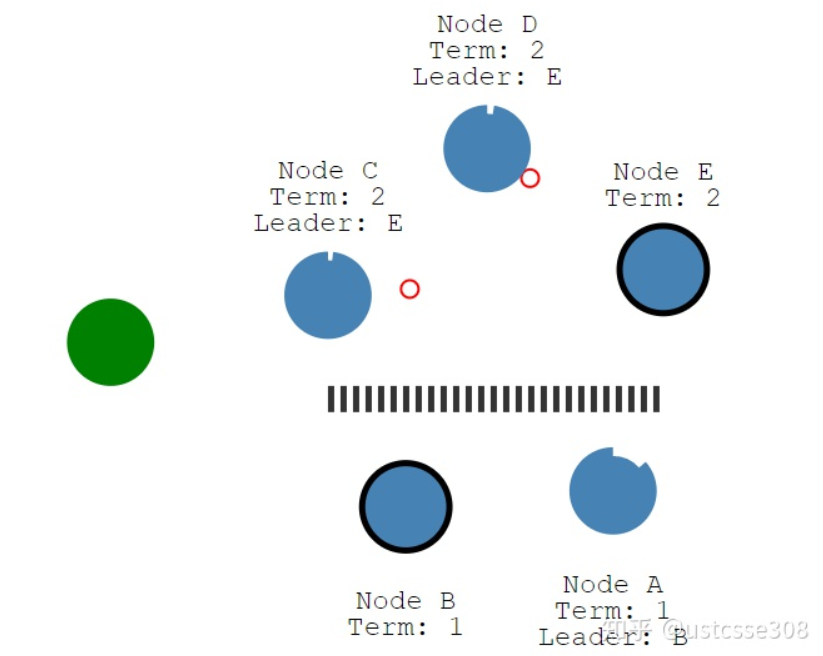
客户端与Leader连接的方式:
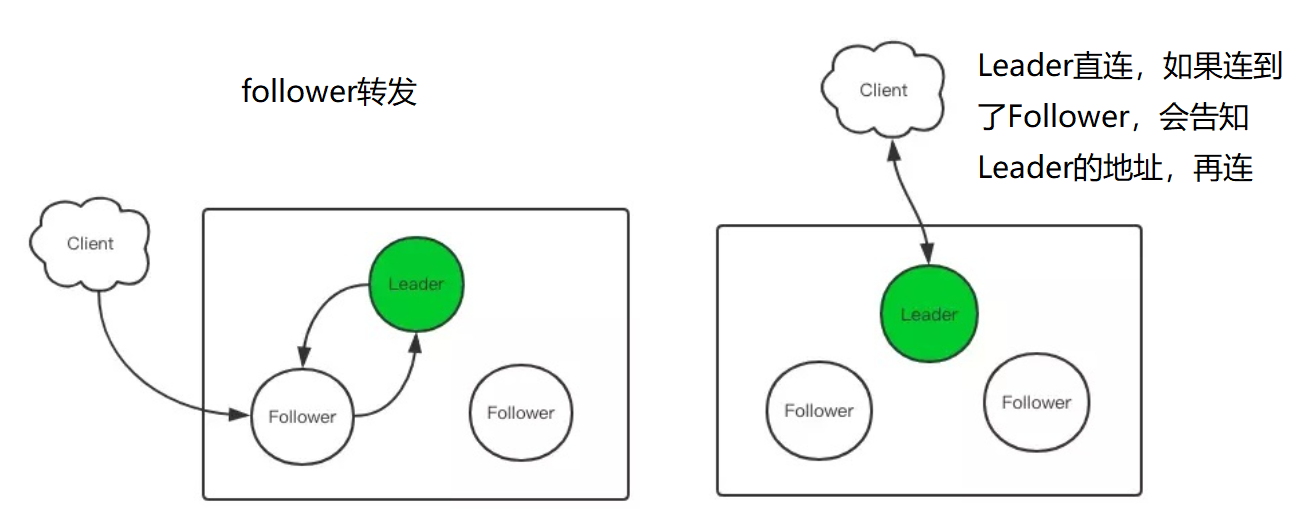
如上图,网络分区了,两个分区无法通信,term1 B是Leader,但是之后出现了网络分区,E选举为term2的Leader。这种情况下的读写:写自然需要majority的响应,读呢?表面看只要和Leader联系就可以了,但是可能由于网络分区读取到严重滞后的数据(如连接到了Node B),所以读也需要majority。
state machine safety:
如果一个节点某一个位置的log entry应用到了状态机,其他节点在同一位置不能应用不同的log entry。
可能出现的违背这个原则的情况:
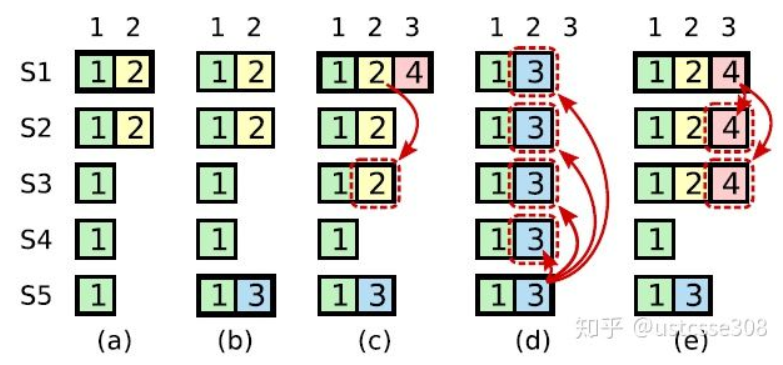
如上图:a时,s1是leader,但是term2的日志只复制到S2,S1就挂了。b时刻,S5成为Leader,日志只在S5保存了,还没来得及分发,S5就挂了,c时刻,S1成为Leader,开始复制日志,复制到S3,此时term2的日志已经复制到了majority,因此committed,可以被状态机应用,然后S1又挂了。d时刻,S5当选,将term3的日志复制到所有节点,但是就可能涉及到已经被应用的log(如term2,已经被大多数应用)的回滚。问题在于term4时Leader S1在c时刻提交了term2任期的日志。解决办法在于S1不能只提交term2,而是和最新的term4一起提交了。这样,有三个节点的日志有了term4,接下来S5就不会当选,就不会出现日志回滚的情况。
总结下就是:某个leader选举成功之后,不会直接提交前人leader时期的日志,而是提交当前任期的日志时一起把之前的日志提交了。在Leader任期开始的时候立刻尝试复制,提交一条空的log。
OK,记的乱的一批,但是读下来还是能有理解的。
Leader Election
每个Raft节点有一个选举定时器,如果在定时器时间耗尽之前,当前节点没有收到任何当前Leader的消息,这个节点会认为Leader已经下线。前面基本都提过。
Election Timer
Raft节点收到AppendEntries消息之后,会重置所有的Raft节点的选举定时器。空AppendEntries作为心跳,Leader定时发出心跳。
之前提到过的选举失败的情况,例如每个时刻所有节点都给自己投票,就选不出Leader,这个时候就是失败,没有Leader给节点发送AppendEntries消息,所以Election Timer到时后会重新开始选举。这个状态应当可以通过为选举定时器设置随机超时时间,防止某一时刻节点同时选举或者出现同时选举之后下次随机就不会同时选举了。
选举定时器的超时时间至少要大于Leader的心跳间隔。但是由于心跳可能会出现网络延迟,所以下限可能要设置成心跳的几倍间隔。选举定时器的上限影响了系统能多快从故障中恢复。
不同节点的选举定时器的超时时间差要足够长,使得第一个开始选举的结点能够完成一轮选举。普遍情况应至少大于一条RPC所需要的的往返时间。
异常情况
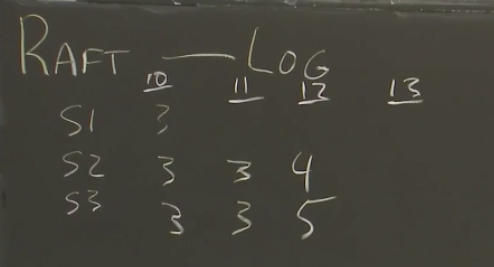
假设下一个term是6,S3被选为term6的Leader,新Leader会发送term6的第一个AppendEntries RPC,这个Log应该位于槽位13。
这个发送的消息是要发送给Follower,并且要带上prevLogIndex和prevLogTerm,也就是12和5,Follower收到AppendEntries消息之后,在写入log之前,会检查前一个Log条目,看是否和prev匹配。
S2明显prev对不上,它会拒绝这个AppendEntries,返回False给Leader,S1在12id上还没有Log,所以也拒绝。
Leader会维护每个follower的nextIndex,收到Follower的false之后,会将nextIndex-1。例如S2,下一个收到的就是12id位置的entry,对应的prevLogIndex为11,prevLogTerm是3,能对应上,所以S2会接受这个Entry,删除原来的条目,换上Leader发给它的新条目。Leader收到Follower的确认消息之后,会增加响应的nextIndex。
为啥可以安全删除log呢?
如上图:a时,s1是leader,但是term2的日志只复制到S2,S1就挂了。b时刻,S5成为Leader,日志只在S5保存了,还没来得及分发,S5就挂了,c时刻,S1成为Leader,开始复制日志,复制到S3,此时term2的日志已经复制到了majority,因此committed,可以被状态机应用,然后S1又挂了。d时刻,S5当选,将term3的日志复制到所有节点,但是就可能涉及到已经被应用的log(如term2,已经被大多数应用)的回滚。问题在于term4时Leader S1在c时刻提交了term2任期的日志。解决办法在于S1不能只提交term2,而是和最新的term4一起提交了。这样,有三个节点的日志有了term4,接下来S5就不会当选,就不会出现日志回滚的情况。
总结下就是:某个leader选举成功之后,不会直接提交前人leader时期的日志,而是提交当前任期的日志时一起把之前的日志提交了。在Leader任期开始的时候立刻尝试复制,提交一条空的log。
选举约束
哪些可以选举成为Leader?
为什么不选择最长Log的节点作为Leader?
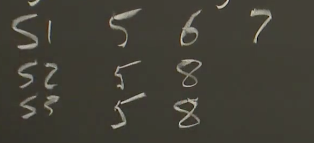
S2和S3组成过半服务器,很可能term8的log已经提交了,所以S1不能当选Leader(会覆盖term8)。
Raft有选举机制:Election Restriction,满足下面条件之一:
- 候选人最后一条Log entry的term大于本地最后一条log entry的term。
- 候选人最后一条log entry的term等于本地最后一条log entry的term,而且候选人的log记录长度大于等于本地Log记录的长度。
再看刚才的例子,如果S2收到了S1的RequestVote RPC,S1最后一条log的term是7,没有人会给它投票。
快速恢复 Fast Backup
可能出现的场景是:一台机器下线了,过了很久才重新上线,那它需要同步的log就非常多,如果是一个一个回退,可能需要大量时间。这里就有一些加速策略。如每次Leader以term为单位进行回退,二分等加速思想。
知道会出现这个问题,需要一些加速策略就行了。
Persistence
有些数据需要持久化存储,一台掉线了其实无所谓,可以根据别的机器的状态导过来。可能整个集群都断电了。供电恢复之后怎么获取状态?还是要持久化存储。
Raft的思想里,只有三个数据需要持久化存储:
log:恢复状态的依据
currentTerm:不然恢复后可能会从紧接着旧log的term+1,但是实际上可能已经term跳了很多了。

比如原来的状态是红框里面的,恢复之后,S2,S3认为下一个term是6,同一个idx就有了不同的term6。
votedFor:不然恢复后可能会重复投票
但是持久化这里也有效率问题,可以通过批量操作等提升性能。例如对于大量的客户端请求,同时接收他们,但是等累积100个之后,再发送AppendEntries。
Log snapshot
对于运行很久的机器,log非常多,如果加入新机器等,要复制的状态可能就多的离谱,而这些操作里面可能包含对同一个元素多次赋值等操作,所以可以考虑保存应用程序的状态。同时也减少了内存消耗。
例如,每10MB log做一个状态快照。删除对应的log。
但是有时候还是会需要早期的log,比如,一个log迟迟没有复制到一个follower上,Leader可能要等很久才能保存快照,或者用一个新的消息类型InstallSnapshot RPC。
就是如果Follower的最新log比Leader最早拥有的log还要早,Leader就发送快照给Follower,Leader有的log正常通过appendEntries发送给Follower。
Linearizability
实际的请求顺序:其中w1代表写入元素1。两个竖线代表客户端发出请求,得到响应。

逻辑顺序(相当于一堆客户端穿行访问,怎么串行返回):
W1 -> R1 -> W2 -> R2
生成这样结果的系统是一个线性一致的系统。条件:
- 如果一个操作在另一个操作前面就结束了,那么执行历史必须在另一个操作的前面。
- 执行历史中,读操作必须在对应的写操作之后。
如果只有写操作,很难判断线性一致,没有读的,不知道写了啥。
一个例子:
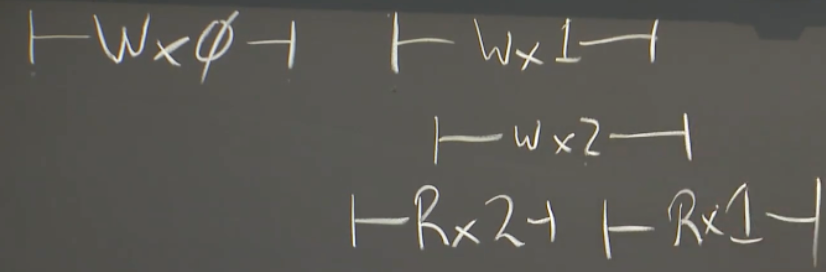
这个是不是线性一致的?
W0 -> w2 -> r2 -> w1 -> r1。是线性一致的。
| ---w1---|的意思是写入1可能在竖线内的任何区域。
实际执行时间,x:
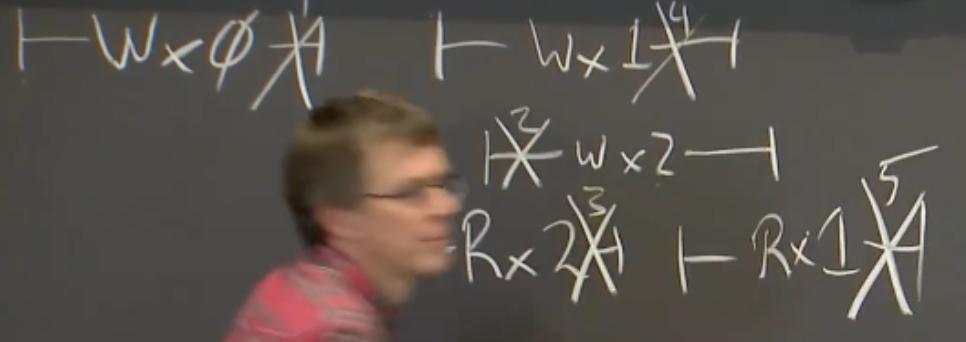
另一个例子:
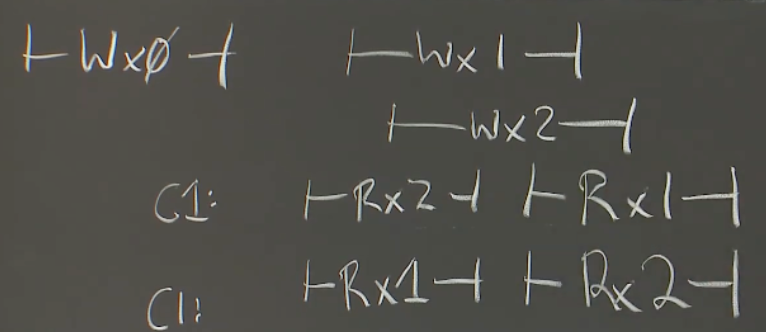
线性一致系统:所有的客户端必须感受到相同的序列。
上面例子可能出现的原因:多个服务器有X的拷贝,但是不同时间他们的值不同。这里不是线性一致。
线性一致不是有关系统设计的定义,是有关系统行为的定义。不能说一个系统设计是线性一致的,而是在系统运行的时候观察它,行为是不是线性一致的。
另另一个例子:
这个明显不是线性一致的,为什么一个系统可能提供旧的数据呢?
可能有大量的副本,每个副本没有看到所有commit了的写请求。有的副本只看到了写1,有的副本只看到了写2,所以向一个拖后腿的副本请求数据时,就会得到x1的值。但是一个线性一致的系统不允许读出旧值。
NO STALE DATA.
重发的例子:
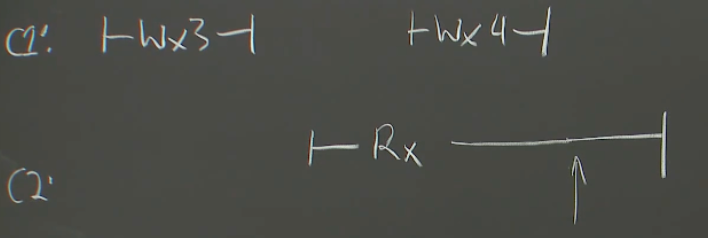
箭头处是客户端重发。
这种情况收到3或者4都是合理的,4很容易理解。
3的话,重传是一个底层行为,或许是RPC的实现里面或者一些库里。从客户端角度讲,只知道在第一条竖线处发送了一个请求。
服务器处理重复请求的合理方式:根据请求的唯一id,维护一个表,如果见到相同的请求,不再执行,返回缓存。
总结
看了几天终于看完了,接下来做lab2实验。