MySQL和Redis的一些问题
Redis内存数据库,如果断电或者宕机数据怎么恢复
如果数据量比较小,直接通过后台数据恢复。
AOF和RDB。
AOF和RDB的具体流程,先写日志还是先写内存?
AOF
AOF日志记录的是所执行的每一条操作指令,先执行命令,把数据写入内存,然后才记录日志。
只有命令执行成功,才会被记录到日志中,否则,系统就会直接向客户端报错,避免记录错误命令。不会阻塞当前写操作。
风险
执行完当前的命令,还没来得及记日志就宕机了,数据丢失。
写回策略
同步写回:命令执行完,立刻日志写磁盘。基本不丢失数据,但是会影响主线程性能。
每秒写回:命令执行完,先写入AOF文件的内存缓冲区,每隔一秒写回。宕机会丢失一秒的数据。
操作系统控制何时写回:写内存缓冲区,操作系统决定何时写回磁盘。
文件太大
重写机制。会有一个后台子进程完成,不会阻塞子进程。
缺点
恢复数据还是一条命令一条命令执行恢复的,过程比较慢。
RDB
直接save是在主线程执行,会导致主线程阻塞;bgsave会fork子进程。
生成RDB的时候会fork一个子进程进行。快照形式保存数据,对某一个时间点的全量数据持久化到磁盘保证数据不丢失,如果redis宕机了可以读取RDB文件来恢复数据。
这个过程会把大量的数据写入磁盘,时间比较长,为了防止阻塞主进程导致redis长时间服务不可用,会fork一个子进程来进行快照。
进行快照的时候redis还是可以提供服务的,会牵扯到内存的数据动态变化。COW,copy on write。为了不影响快照数据,会将当前时间内存的数据(数据的内存地址)拷贝一份出来。只有在redis内存中对应的数据修改的时候,才会把原数据拷贝到一个新的内存地址,然后RDB对应数据的引用会指向新的内存地址。通过这种方式保证RDB子进程和父进程的数据修改相互不影响。
RDB fork子进程写日志时如果宕机是不是会有数据丢失,怎么解决?
AOF和RDB结合使用
单key过热怎么解决
热key,瞬间有大量请求去访问某个key,可能会压垮缓存服务。
如何发现
- 业务经验预估
- 客户端收集。操作redis之前,进行数据统计。会对客户端代码造成入侵。
- 在proxy层收集。
- redis带的分析工具,比如monitor命令,会实时抓取出redis服务器收到的命令,然后可以写代码统计热key。
如何解决
二级缓存
在应用层缓存,热key不走redis。
备份热key
在多个redis存一份热key的备份。
大key问题怎么解决
其实是大value问题。可能后果:阻塞线程,并发量下降,客户端超时,服务端业务成功率下降。
如何产生的
一直添加数据,没有删除机制。
没有合理做分片,大key变成小key。
解决
删除:渐进删除,惰性删除
不可删除的话:value压缩、value拆分
并发编程无锁编程,JUC包类
Java中的无锁编程本质上就是CAS机制,CAS是一个原子性操作,目前大部分的CPU都支持CAS操作,能够在硬件层面实现原子性。
Java中java.util.concurrent中提供了一些实现原子操作的类,AtomicInteger, AtomicBoolean, AtomicLong...
AtomicInteger怎么保证原子性
CAS操作,调用的是unsafe下面的compareAndSwap函数
CAS过程,ABA问题
版本号
频繁FULL GC如何排查
- 检查JVM配置、新生代、老年代大小
- 观察老年代使用情况,每次FULL GC后内存变化,如果FULL GC后内存还是占用很大,考虑内存泄露情况。对比上次上线代码,code review。
- jmap查看堆内存的对象,排序,锁定可能出问题的对象,例如int[]
- dump堆文件,通过可视化工具分析。找到对应大对象所属的业务对象。
thrift、protobuf
thrift是一个RPC框架,通过Thrift规范定义接口,然后䚒Thrift编译器生成各种编程语言代码。
protobuf:性能好,只涉及序列化和反序列化技术,不涉及RPC功能。
MySQL架构
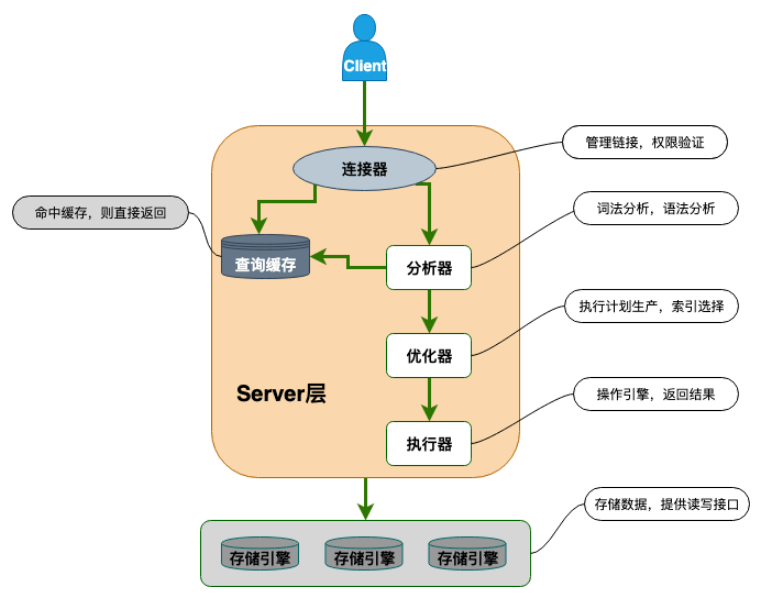
查询缓存:8.0版本后去除。
MySQL中MyISAM和InnoDB区别
| MyISAM | InnoDB |
|---|---|
| 只有表级锁 | 行级锁和表级锁,默认表级锁 |
| 不支持事务 | 支持事务,四个隔离级别 |
| 不支持外键 | 支持外键 |
| 不支持数据库崩溃恢复 | 支持(redo log) |
InnoDB 的默认隔离级别 RR(可重读)是可以解决幻读问题发生的,主要有下面两种情况:
- 快照读(一致性非锁定读) :由 MVCC 机制来保证不出现幻读。
- 当前读 (一致性锁定读): 使用 Next-Key Lock 进行加锁来保证不出现幻读。
聚集索引和非聚集索引
聚集索引
优点:查询速度快,B+树本身就是一个多叉平衡树,叶子结点也是有序的,定位到索引位置,就相当于定位到了数据。
缺点:如果索引的数据不是有序的,就需要在插入时排序,如果是字符串或者UUID这种又长又难比较的数据,插入和查找的速度都比较慢。
非聚集索引
索引结构和数据分开存放的索引。
优点:更新代价比聚集索引小,非聚集索引的叶子节点是不存放数据的。
缺点:二次查询。
redo log
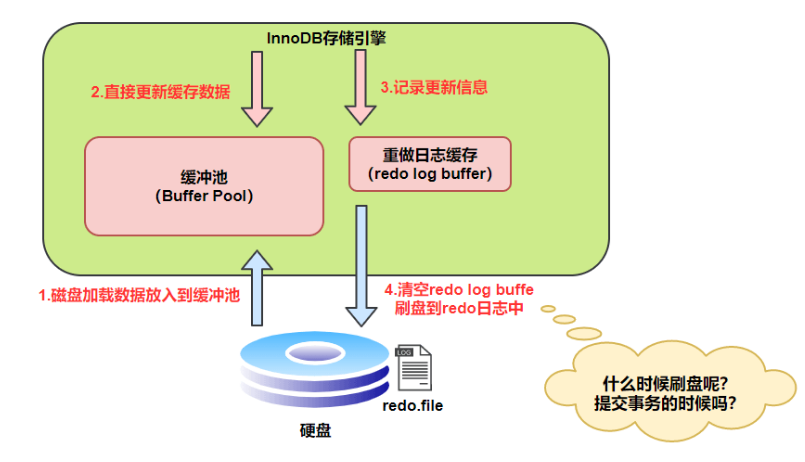
刷盘时机:每次提交、每秒、系统控制。
为啥要redo log而不是修改数据页后直接刷盘
数据页刷盘是随机写,redo log是顺序写。
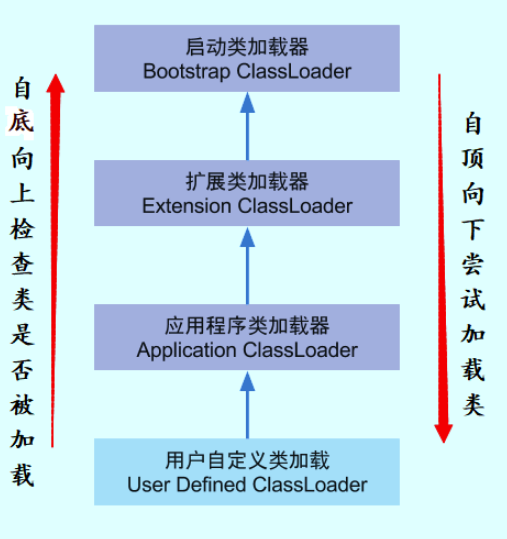
类加载器
Java中IO
BIO
步阻塞 IO 模型中,应用程序发起 read 调用后,会一直阻塞,直到内核把数据拷贝到用户空间。
NIO
non-blocking IO,可以认为是IO多路复用模型。
AIO
异步 IO 是基于事件和回调机制实现的,也就是应用操作之后会直接返回,不会堵塞在那里,当后台处理完成,操作系统会通知相应的线程进行后续的操作。